
# Hybrid Search
NOTE
This guide is only applicable to the DB version 1.6.2 or higher.
This guide explains how to perform full-text and vector hybrid search in MyScale.
Full-text search and vector search each have their own strengths and weaknesses. Full-text search is great for basic keyword retrieval and text matching, while vector search excels at cross-document semantic matching and deep understanding of semantics but may lack efficiency with short text queries. Hybrid search combines the benefits of both approaches, enhancing accuracy and speed in text searches to meet users' expectations for precise results efficiently.
# Tutorial Overview
This guide covers:
- The Wikipedia dataset and the embedding model used for hybrid search.
- Instructions on creating tables and building indexes.
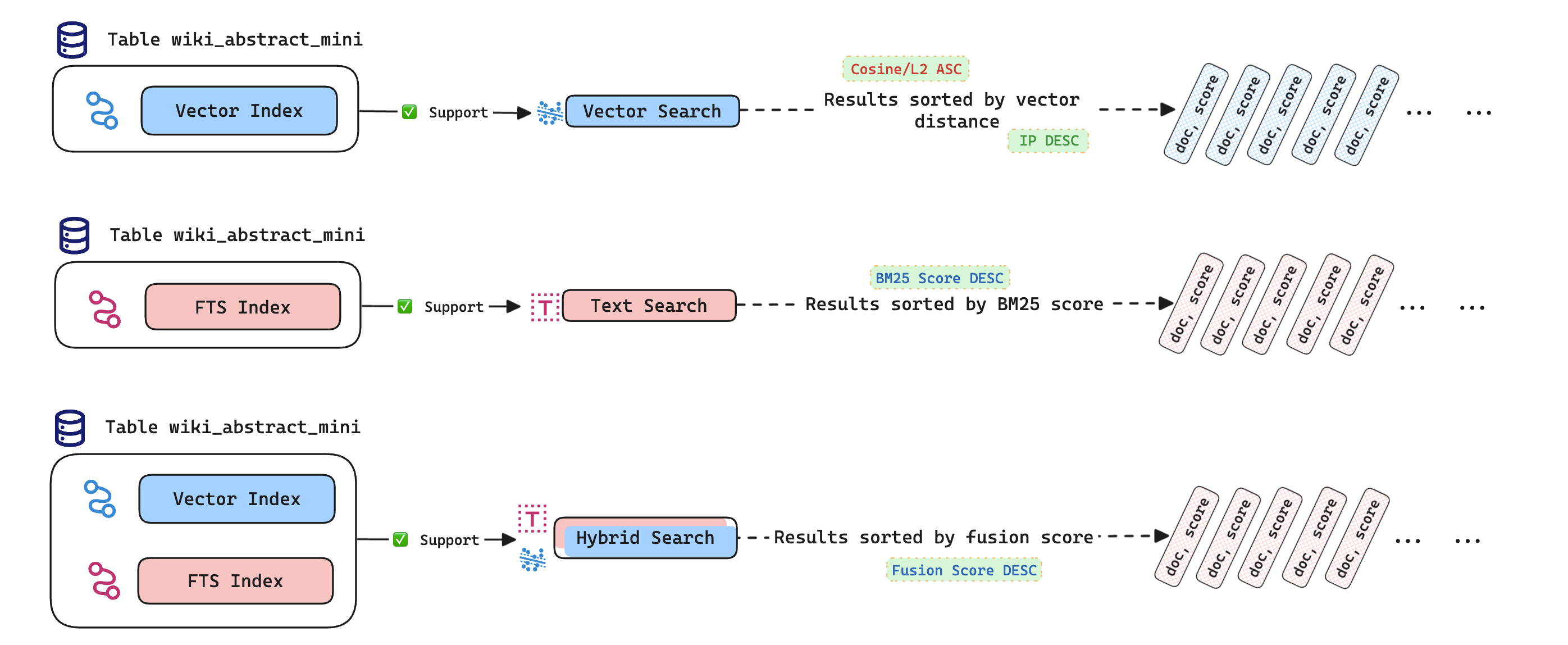
- How to use the
HybridSearch()function. - Examples of performing vector, text, and hybrid searches.
The HybridSearch() function combines the results of vector and text searches, enhancing adaptability across different scenarios and improving search accuracy.
Before starting, ensure you have a MyScale cluster set up. For setup instructions, refer to our Quickstart Guide (opens new window).
# Dataset
The experiment utilized the Wikipedia abstract dataset (opens new window) provided by RediSearch, comprising 5,622,309 document entries. We selected the first 100,000 entries and processed them using the multilingual-e5-large (opens new window) model to create 1024-dimensional vectors stored in the body_vector column. Similarity between vectors was calculated using cosine distance.
TIP
For more information on how to use multilingual-e5-large, please refer to HuggingFace's documentation (opens new window).
The dataset wiki_abstract_100000_1024D.parquet (opens new window) has a size of 668MB, contains 100,000 entries. You can preview its contents below without needing to download it locally since we will import it directly into MyScale via S3 in subsequent experiments.
| id | body | title | url | body_vector |
|---|---|---|---|---|
| ... | ... | ... | ... | ... |
| 78 | A total solar ... the Sun for a viewer on Earth. | Solar eclipse of November 12, 1985 | https://en.wikipedia.org/wiki/Solar_eclipse_of_November_12,_1985 (opens new window) | [1.4270141,...,-1.2265089] |
| 79 | Dhamangaon Badhe is a town ... Aurangabad districts. | Dhamangaon Badhe | https://en.wikipedia.org/wiki/Dhamangaon_Badhe (opens new window) | [0.6736672,....,0.12504958] |
| ... | ... | ... | ... | ... |
# Table Creation and Data Import
To create the table wiki_abstract_mini in MyScale's SQL workspace, execute the following SQL statement:
CREATE TABLE default.wiki_abstract_mini(
`id` UInt64,
`body` String,
`title` String,
`url` String,
`body_vector` Array(Float32),
CONSTRAINT check_length CHECK length(body_vector) = 1024
)
ENGINE = MergeTree
ORDER BY id
SETTINGS index_granularity = 128;
Import data from S3 into the table. Please be patient during the data import process.
INSERT INTO default.wiki_abstract_mini
SELECT * FROM s3('https://myscale-datasets.s3.ap-southeast-1.amazonaws.com/wiki_abstract_100000_1024D.parquet', 'Parquet');
Note
The estimated time for data import is approximately 10 minutes.
Verify if there are 100,000 rows of data in the table by running this query:
SELECT count(*) FROM default.wiki_abstract_mini;
Output:
| count() |
|---|
| 100000 |
# Build Index
# Create FTS Index
TIP
To learn how to create an FTS index, please consult the text search documentation.
When setting up an FTS index, users have the option to customize the tokenizer. In this example, the stem tokenizer is utilized along with applying stop words. The stem tokenizer can overlook word tenses in text for more precise search outcomes. By using stop words, common words like "a", "an", "of", and "in" are filtered out to enhance search accuracy.
ALTER TABLE default.wiki_abstract_mini
ADD INDEX body_idx (body)
TYPE fts('{"body":{"tokenizer":{"type":"stem", "stop_word_filters":["english"]}}}');
Execute materialization of the index:
ALTER TABLE default.wiki_abstract_mini MATERIALIZE INDEX body_idx;
# Create Vector Index
TIP
Learn more about the MSTG vector index in the vector search documention.
To create the MSTG vector index using Cosine distance for the body_vec_idx on the default.wiki_abstract_mini table, run this SQL statement:
ALTER TABLE default.wiki_abstract_mini
ADD VECTOR INDEX body_vec_idx body_vector
TYPE MSTG('metric_type=Cosine');
Building a vector index can be time-consuming. To monitor its progress, run this SQL query. If the status column shows Built, the index has been successfully created. If it displays InProgress, the process is still ongoing.
SELECT * FROM system.vector_indices;
# HybridSearch Function
The HybridSearch() function in MyScale performs hybrid searches by combining vector and text search results, returning the top candidates. The basic syntax is:
HybridSearch('dense_param1 = value1', 'param2 = value2')(vector_column, text_column, query_vector, query_text)
params: Search-specific parameters. Parameters starting withdense_are for vector search. For example,dense_alphasets thealphaparameter for the MSTG vector index.vector_column: Column containing the vector data to be searched.text_column: Column containing the text data to be searched.query_vector: Vector to be searched.query_text: Text to be searched.
Use the HybridSearch function with an ORDER BY clause and a LIMIT clause to retrieve the top candidates. The sorting direction for columns in the ORDER BY clause must be set to DESC.
# HybridSearch Parameters Explained
Below is a detailed description of the HybridSearch() parameters:
| Parameter | Default Value | Candidate Values | Description |
|---|---|---|---|
fusion_type | N/A | rsf, rrf | Determines the combination method in hybrid search. rsf stands for Relative Score Fusion, and rrf stands for Reciprocal Rank Fusion. This parameter is required. |
fusion_weight | 0.5 | Floating point number between 0 - 1 | Specifies the weight |
fusion_k | 60 | Positive integer no less than 1 | Specifies the sorting constant |
enable_nlq | true | true, false | Indicates whether to use natural language queries in text search. |
operator | OR | OR, AND | Specifies the logical operator used to combine terms in text search. |
# Fusion Types
Hybrid search combines the BM25 score from text searches (denoted as
- Relative Score Fusion (RSF): In RSF, scores from both vector and text searches are normalized between 0 and 1. The highest raw score is set to 1, while the lowest is set to 0, with all other values proportionally ranked within this range. The final score is a weighted sum of these normalized scores:
The normalization formula used is:
- Reciprocal Rank Fusion (RRF): RRF does not require score normalization. Instead, it ranks results based on their positions in each result set using the following formula, where
# Perform Vector, Text and Hybrid Search
# Create an Embedding Function
To convert query text into vectors, we will use the multilingual-e5-large (opens new window) model.
Thanks to MyScale's embedding functions, converting text to vectors online is straightforward. We will create an embedding function, MultilingualE5Large, for this purpose.
TIP
You need a free key from HuggingFace to create an embedding function.
CREATE FUNCTION MultilingualE5Large
ON CLUSTER '{cluster}' AS (x) -> EmbedText (
concat('query: ', x),
'HuggingFace',
'https://api-inference.huggingface.co/models/intfloat/multilingual-e5-large',
'<your huggingface key, starts with `hf_`>',
''
);
# Execute Vector Search
TIP
The British Graham Land expedition (BGLE) was a British expedition. For detailed information about them please refer to Wikipedia (opens new window).
Vector search generally performs well in the domain of long texts, but its effectiveness may diminish in the realm of short texts. To illustrate the search performance across different text lengths, we will present two examples of vector searches. The content we are searching for pertains to locations marked by the BGLE expedition team, with the difference between the two sentences being whether or not the team’s name abbreviation is used.
- Example 1. long text query: 'Charted by the British Graham Land Expedition'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Charted by the British Graham Land Expedition')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
From the search results below, it is evident that vector search excels in matching long texts, with four out of the top five search results meeting our criteria.
| id | title | body | score |
|---|---|---|---|
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.17197883 |
| 16459 | Link Stack | Link Stack () is a rocky pillar at the northwest end of Chavez Island, off the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37. | 0.17324567 |
| 47359 | Huitfeldt Point | Huitfeldt Point is a point southeast of Vorweg Point on the southwest side of Barilari Bay, on the west coast of Graham Land, Antarctica. It was charted by the British Graham Land Expedition under John Rymill, 1934–37, and was named by the UK Antarctic Place-Names Committee in 1959 for Fritz R. | 0.17347288 |
| 48138 | Santos Peak | Santos Peak () is a peak lying south of Murray Island, on the west coast of Graham Land. Charted by the Belgian Antarctic Expedition under Gerlache, 1897-99. | 0.17546016 |
| 15482 | Parvenu Point | Parvenu Point () is a low but prominent point forming the north extremity of Pourquoi Pas Island, off the west coast of Graham Land. First surveyed in 1936 by the British Graham Land Expedition (BGLE) under Rymill. | 0.17611909 |
- Example 2. short text query: 'Charted by the BGLE'
SELECT
id,
title,
body,
distance('alpha=3')(body_vector, MultilingualE5Large('Charted by the BGLE')) AS score
FROM default.wiki_abstract_mini
ORDER BY score ASC
LIMIT 5;
However, when examining the search results for short texts, it becomes clear that vector search is less effective in this domain, as none of the top five documents contain any information about BGLE.
| id | title | body | score |
|---|---|---|---|
| 17693 | Têtes Raides | | current_members = Christian OlivierGrégoire SimonPascal OlivierAnne-Gaëlle BisquaySerge BégoutÉdith BégoutPierre GauthéJean-Luc MillotPhilippe Guarracino | 0.19922233 |
| 92351 | Badr al-Din Lu'lu' | right|thumb|250px|Badr al-Din Lu'lu', manuscript illustration from the Kitāb al-Aghānī of [[Abu al-Faraj al-Isfahani (Feyzullah Library No. 1566, Istanbul). | 0.19949186 |
| 45934 | Singing All Along | |show_name_2=|simplified=|pinyin=Xiùlì Jiāngshān Zhī Cháng Gē Xíng|translation=Splendid and Beautiful Rivers and Mountains: Long Journey of Songs}} | 0.2003029 |
| 44708 | LinQ | | current_members =Yumi TakakiSakura ArakiAyano YamakiMYUChiaki Sara YoshikawaRana KaizukiAsaka SakaiKana FukuyamaManami SakuraMaina KohinataChisa Ando | 0.20089924 |
| 43706 | Shorty (crater) | | diameter = 110 mShorty, Gazetteer of Planetary Nomenclature, International Astronomical Union (IAU) Working Group for Planetary System Nomenclature (WGPSN) | 0.20098251 |
# Execute Text Search
BM25, a widely-used text search algorithm, is highly mature and particularly suitable for short text matching. However, when it comes to understanding the semantics of long texts, BM25 is not as effective as vector search. The following demonstrates the powerful search capabilities of TextSearch() in the field of short text.
- Example. short text query: 'Charted by the BGLE'
SELECT
id,
title,
body,
TextSearch(body, 'Charted by the BGLE') AS bm25_score
FROM default.wiki_abstract_mini
ORDER BY bm25_score DESC
LIMIT 5;
| id | title | body | bm25_score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.392099 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 15.126007 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
| 49006 | Somers Glacier | Somers Glacier () is a glacier flowing northwest into Trooz Glacier on Kiev Peninsula, the west coast of Graham Land. First charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 14.620504 |
# Execute Hybrid Search
MyScale provides the HybridSearch() function, a search method that combines the strengths of vector search and text search. This approach not only enhances the understanding of long text semantics but also addresses the semantic shortcomings of vector search in the short text domain.
- Example. short text query: Charted by the BGLE
SELECT
id,
title,
body,
HybridSearch('fusion_type=RSF', 'fusion_weight=0.6')(body_vector, body, MultilingualE5Large('Charted by the BGLE'), ' BGLE') AS score
FROM default.wiki_abstract_mini
ORDER BY score DESC
LIMIT 5;
Based on the results obtained from the HybridSearch() function, we can achieve excellent search outcomes even when searching short texts, with significantly enhanced accuracy.
| id | title | body | score |
|---|---|---|---|
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.6 |
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 48775 | Sohm Glacier | Sohm Glacier () is a glacier flowing into Bilgeri Glacier on Velingrad Peninsula, the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.5404912 |
| 49000 | Sooty Rock | Sooty Rock () is a rock midway between Lumus Rock and Betheder Islands in Wilhelm Archipelago. Discovered and named "Black Reef" by the British Graham Land Expedition (BGLE), 1934-37. | 0.5404912 |
| 14327 | Trout Island | Trout Island () is an island just east of Salmon Island in the Fish Islands, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.4274415 |
From DB version v1.8 or higher, the text search column in the HybridSearch() function is allowed from a multi-columns FTS index.
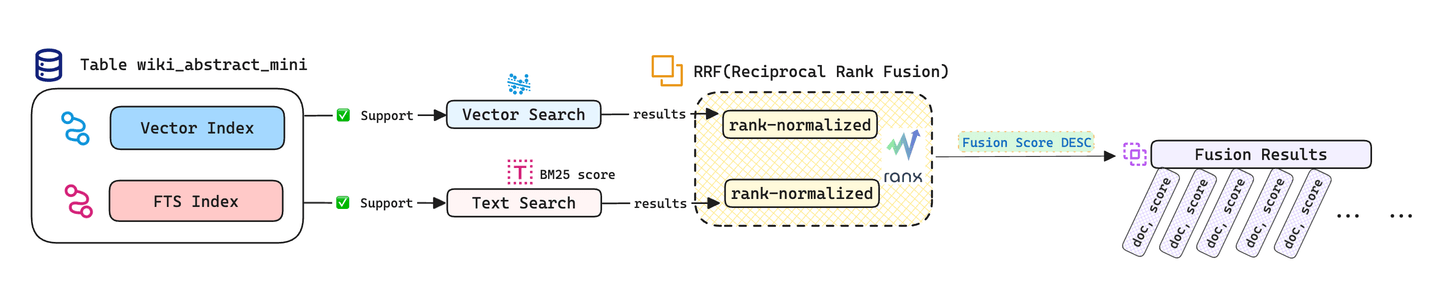
# Hybrid Search Outside the Database
We can also utilize the ranx (opens new window) library in Python to combine vector and text search results outside the database, implementing the RRF fusion strategy (Reciprocal Rank Fusion) to enhance search accuracy. For alternative fusion strategies, you can consult ranx/fusion (opens new window).
Before run the demo code below, you should intall the ranx:
pip install -U ranx
Sample code in Python:
import clickhouse_connect
from numba import NumbaTypeSafetyWarning
from prettytable import PrettyTable
from ranx import Run, fuse
from ranx.normalization import rank_norm
import warnings
warnings.filterwarnings('ignore', category=NumbaTypeSafetyWarning)
# MyScale information
host = "your cluster end-point"
port = 443
username = "your user name"
password = "your password"
database = "default"
table = "wiki_abstract_mini"
# Init MyScale client
client = clickhouse_connect.get_client(host=host, port=port, username=username, password=password)
# Use a table to output your content
def print_results(result_rows, field_names):
x = PrettyTable()
x.field_names = field_names
for row in result_rows:
x.add_row(row)
print(x)
# We want search a short text.
terms = "Charted by BGLE"
# Execute VectorSearch.
vector_search = f"SELECT id, title, body, distance('alpha=3')" \
f"(body_vector, MultilingualE5Large('{terms}')) AS distance FROM {database}.{table} " \
f"ORDER BY distance ASC LIMIT 100"
vector_search_res = client.query(query=vector_search)
# Execute TextSearch.
text_search = f"SELECT id, title, body, TextSearch(body, '{terms}') AS score " \
f"FROM {database}.{table} " \
f"ORDER BY score DESC LIMIT 100"
text_search_res = client.query(query=text_search)
# Extract VectorSearch and TextSearch results.
stored_data = {}
for row in vector_search_res.result_rows:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
for row in text_search_res.result_rows:
if str(row[0]) not in stored_data:
stored_data[str(row[0])] = {"title": row[1], "body": row[2]}
# Extract id and score from results.
bm25_dict = {"query-0": {str(row[0]): float(row[3]) for row in text_search_res.result_rows}}
# For ranx library, a higher score is expected to indicate greater relevance,
# thus preprocessing is required for vector distance calculation methods such as Cosine and L2.
max_value = max(float(row[3]) for row in vector_search_res.result_rows)
vector_dict = {"query-0": {str(row[0]): max_value - float(row[3]) for row in vector_search_res.result_rows}}
# Normalize query results score.
vector_run = rank_norm(Run(vector_dict, name="vector"))
bm25_run = rank_norm(Run(bm25_dict, name="bm25"))
# Fusion query results using RRF.
combined_run = fuse(
runs=[vector_run, bm25_run],
method="rrf",
params={'k': 10}
)
print("\nFusion results:")
pretty_results = []
for id_, score in combined_run.get_doc_ids_and_scores()[0].items():
if id_ in stored_data:
pretty_results.append([id_, stored_data[id_]["title"], stored_data[id_]["body"], score])
print_results(pretty_results[:5], ["ID", "Title", "Body", "Score"])
The fusion query results are as follows: Hybrid search accurately matched five articles related to the locations charted by the BGLE expedition, showcasing the benefits of hybrid search for processing short text queries.
| ID | Title | Body | Score |
|---|---|---|---|
| 47415 | Tadpole Island | Tadpole Island () is an island just north of Ferin Head, off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.06432246998284734 |
| 15145 | Paragon Point | Paragon Point () is a small but prominent point on the southwest side of Leroux Bay, 3 nautical miles (6 km) west-southwest of Eijkman Point on the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.049188640973630834 |
| 48165 | Salmon Island | Salmon Island () is the westernmost of the Fish Islands, lying off the west coast of Graham Land. Charted by the British Graham Land Expedition (BGLE) under Rymill, 1934-37. | 0.047619047619047616 |
| 64566 | Want You Back (Haim song) | format=Digital download | recorded= |
| 45934 | Singing All Along | show_name_2= |
# Conclusion
This document provides insights into the usage of MyScale hybrid search, focusing on methods and techniques for searching unstructured text data. In the practical exercise, we developed an example using Wikipedia abstracts. Performing hybrid search is easy with MyScale's advanced full-text and vector search capabilities, and yields more accurate results by combining both keyword and semantic information.