
# チャットデータアプリ
![]()
LangChainとMyScaleを使用して数百万のドキュメント上でChatPDFアプリを30分で構築する
単一の学術論文に関してGPTとチャットすることは比較的簡単で、ドキュメントを言語モデルのコンテキストとして提供することで行うことができます。何百万もの研究論文とチャットすることも簡単です...ただし、適切なベクトルデータベースを選択する限りです。
大規模言語モデル(LLM)は強力なNLPツールです。ChatGPTなどのLLMの最も重要な利点の1つは、トピックに基づいて、関連のない他の質問ではなく、研究や学術論文のPDFコピーなどのドキュメントと対話(またはチャット)するためのツールを構築できることです。
Chat-with-documentアプリの多くの実装が既に存在していますが、ChatPaper (opens new window)、OpenChatPaper (opens new window)、DocsMind (opens new window)など、これらの実装の多くは複雑で、基本的なメタデータ(年や科目など)に基づいた基本的なキーワード検索フィルタリングのみを備えた単純な検索ユーティリティのみを備えているように見えます。
そのため、数百万の学術/研究論文と対話するためのChatPDFのようなアプリを開発することは合理的です。自然言語でデータとチャットすることで、意味的および構造的な属性の両方を組み合わせることができます。例えば、「ニューラルネットワークとは何ですか?Geoffrey Hintonが2018年以降に発表した論文を使用してください。」
この記事の主な目的は、LangChainとMyScaleを使用して数百万の学術/研究論文と対話(チャット)するための独自のChatPDFアプリを構築するのに役立つことです。
このアプリの作成には約30分かかります。
しかし、始める前に、以下の全体のプロセスのダイアグラムワークフローを見てみましょう:
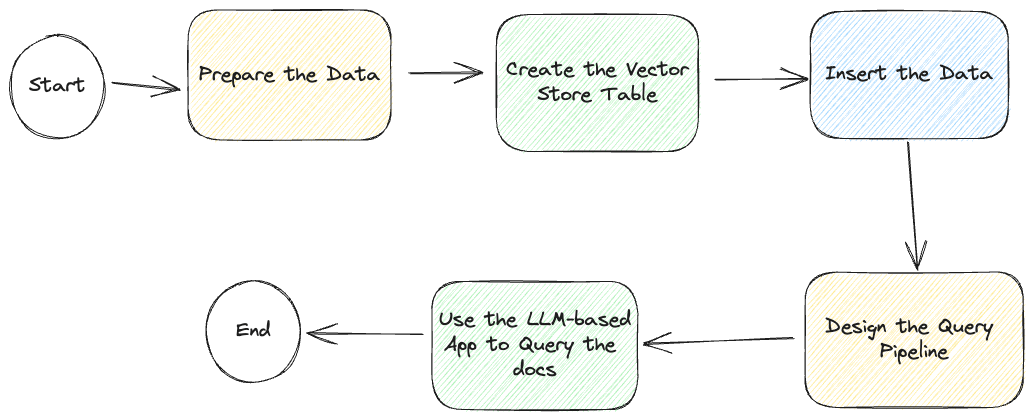
LLMベースのチャットアプリの開発方法について説明しますが、GitHub (opens new window)にサンプルアプリがあり、読み取り専用のベクトルデータベース (opens new window)にアクセスすることもできます。これにより、アプリの作成プロセスがさらに簡素化されます。
# データの準備
このイメージに説明されているように、最初のステップはデータの準備です。
このアプリでは、当社のオープンデータベースを使用することをお勧めします。資格情報は、例の設定ファイル「.streamlit/secrets.toml」にあります。または、以下の手順に従って独自のデータベースを作成することもできます。データベースの作成には約20分かかります。
データは、Macrocosmのウェブサイト (opens new window)を通じてAlexandria Indexからの利用可能な抄録とarXiv IDのリストを入手しました。このデータとarXiv Open APIへの問い合わせにより、年、科目、リリース日、カテゴリ、著者などのより豊富なメタデータセットを取得することができます。
データはパブリックデータベースアクセスで準備されています。以下の資格情報を使用してarxivデータセットを直接操作できます:
MYSCALE_HOST = "msc-950b9f1f.us-east-1.aws.myscale.com"
MYSCALE_PORT = 443
MYSCALE_USER = "chatdata"
MYSCALE_PASSWORD = "myscale_rocks"
OPENAI_API_KEY = "<your-openai-key>"
または、こちらの手順 (opens new window)に従って独自のデータセットを作成することもできます(SQLまたはLangChain)。
素晴らしいです。次のステップに進みましょう。
# LangChain
データをテーブルに挿入するために、LangChainを使用してデータの挿入プロセスをより制御できるようにします。
次のコードスニペットをアプリのコードに追加します:
# ! unzstd data-*.jsonl.zstd
import json
from langchain.docstore.document import Document
def str2doc(_str):
j = json.loads(_str)
return Document(page_content=j['abstract'], metadata=j['metadata'])
with open('func_call_data.jsonl') as f:
docs = [str2doc(l) for l in f.readlines()]
# クエリパイプラインの設計
ほとんどのLLMベースのアプリケーションでは、クエリを実行し、クエリの結果を返すための自動化されたパイプラインが必要です。
LLMベースのチャットアプリでは、モデル(LLM)をクエリする前に参照ドキュメントを取得する必要があります。
以下の図に示すように、アプリがユーザーのクエリに回答する方法をステップバイステップで説明します。
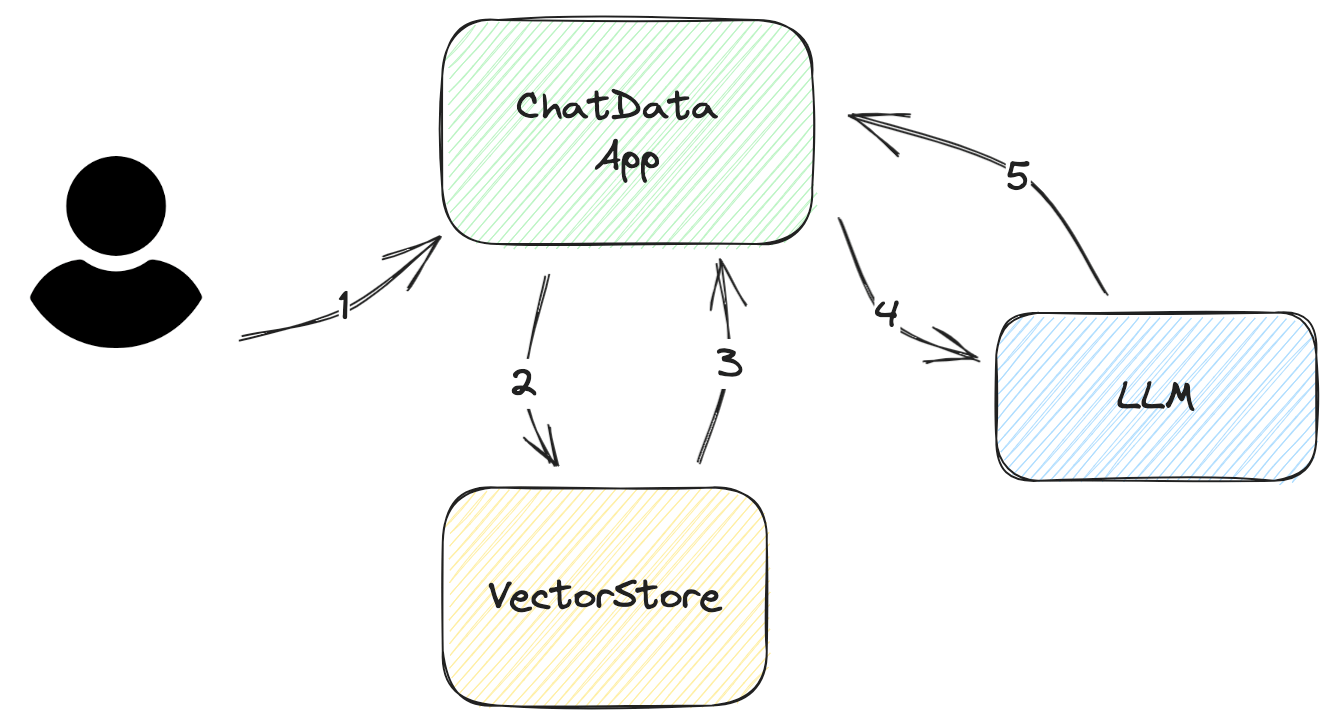
ユーザーの入力/質問を求める この入力はできるだけ簡潔である必要があります。ほとんどの場合、最大でも数文であるべきです。
ユーザーの入力からDBクエリを構築する ベクトルデータベースの場合、クエリは簡単です。関連する埋め込みをベクトルデータベースから抽出するだけです。ただし、より高い精度を得るために、クエリをフィルタリングすることをお勧めします。
たとえば、ユーザーが返された埋め込みにすべての研究論文が含まれているが、ユーザーは最新の論文のみを求めている場合、この課題を解決するために、クエリにメタデータフィルタを追加して正しい情報をフィルタリングすることができます。
VectorStoreから取得したドキュメントを解析する ベクトルストアから返されるデータは、LLMが理解できるネイティブ形式ではありません。データを解析し、プロンプトテンプレートに挿入する必要があります。これらのテンプレートには、作成日、著者、ドキュメントのカテゴリなどのメタデータを追加する必要があります。このメタデータは、LLMが回答の品質を向上させるのに役立ちます。
LLMに質問する このプロセスは、LLMのAPIに精通しており、適切に設計されたプロンプトを持っている限り、簡単です。
回答を取得する シンプルなアプリケーションの場合、回答の返却は簡単です。ただし、質問が複雑な場合は、ユーザーにより多くの情報を提供するために追加の努力が必要です。たとえば、LLMのソースデータを追加することができます。また、プロンプトに参照番号を追加することで、ソースを見つけて、ドキュメントのタイトルなどの繰り返しコンテンツを避けるためにプロンプトのサイズを縮小することができます。
実際には、LangChainにはうまく機能するフレームワークがあります。このパイプラインを構築するために、次の関数を使用しました:
RetrievalQAWithSourcesChainSelfQueryRetriever
# SelfQueryRetriever
この関数は、VectorStoreとアプリの間の対話を定義します。以下の図に示すように、self-query retrieverがどのように機能するかについて詳しく説明します。
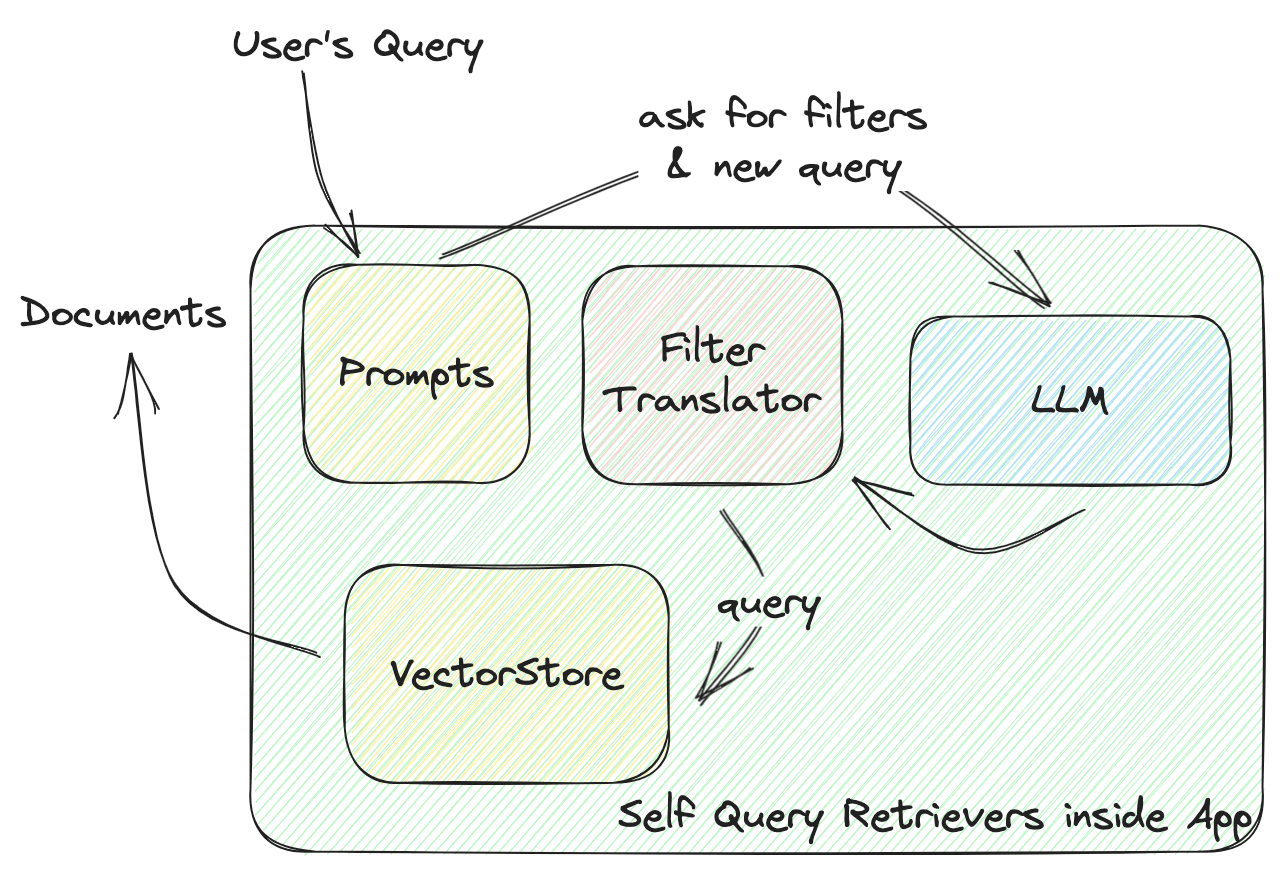
LangChainのSelfQueryRetrieverは、comparators(値を比較するためのもの)とoperators(これらの条件を組み合わせてフィルタを形成するもの)を含む、すべてのVectorStoreに対するユニバーサルフィルタを定義します。LLMは、これらのcomparatorsとoperatorsに基づいてフィルタルールを生成します。すべてのVectorStoreプロバイダは、与えられたユニバーサルフィルタを正しい引数に変換するためのFilterTranslatorを実装します。
LangChainのユニバーサルソリューションは、新しい演算子、比較演算子、およびベクトルストアプロバイダに対して完全なパッケージを提供します。ただし、それにはそれに含まれる事前定義された要素に制限があります。
プロンプトフィルタのコンテキストでは、MyScaleにはより強力で柔軟なフィルタが含まれています。リストやタイムスタンプなどのより多くのデータ型、文字列パターンマッチングやリストのためのCONTAIN比較演算子などのより多くの関数を追加しました。これにより、データの保存とクエリ設計のオプションが増えます。
私たちはLangChainのSelf-Query retrieverに貢献し、より強力なSelf-Query retrieverを提供しました。これにより、クエリの設計時にLLMにより多くの自由度が与えられます。
メタデータフィルタでMyScaleができること (opens new window)を見てみましょう。
以下は、LangChainを使用して記述されたコードです。
from langchain.vectorstores import MyScale
from langchain.embeddings import HuggingFaceInstructEmbeddings
# Assuming you data is ready on MyScale Cloud
embeddings = HuggingFaceInstructEmbeddings()
doc_search = MyScale(embeddings)
# Define metadata fields and their types
# Descriptions are important. That's where LLM know how to use that metadata.
metadata_field_info=[
AttributeInfo(
name="pubdate",
description="The year the paper is published",
type="timestamp",
),
AttributeInfo(
name="authors",
description="List of author names",
type="list[string]",
),
AttributeInfo(
name="title",
description="Title of the paper",
type="string",
),
AttributeInfo(
name="categories",
description="arxiv categories to this paper",
type="list[string]"
),
AttributeInfo(
name="length(categories)",
description="length of arxiv categories to this paper",
type="int"
),
]
# Now build a retriever with LLM, a vector store and your metadata info
retriever = SelfQueryRetriever.from_llm(
OpenAI(openai_api_key=st.secrets['OPENAI_API_KEY'], temperature=0),
doc_search, "Scientific papers indexes with abstracts", metadata_field_info,
use_original_query=True)
# RetrievalQAWithSourcesChain
この関数は、ドキュメントを含むプロンプトを構築します。
データは、JSONやMarkdownなどのLLMが読み取れる形式の文字列にフォーマットする必要があります。これらの文字列には、ドキュメントの情報が含まれている必要があります。
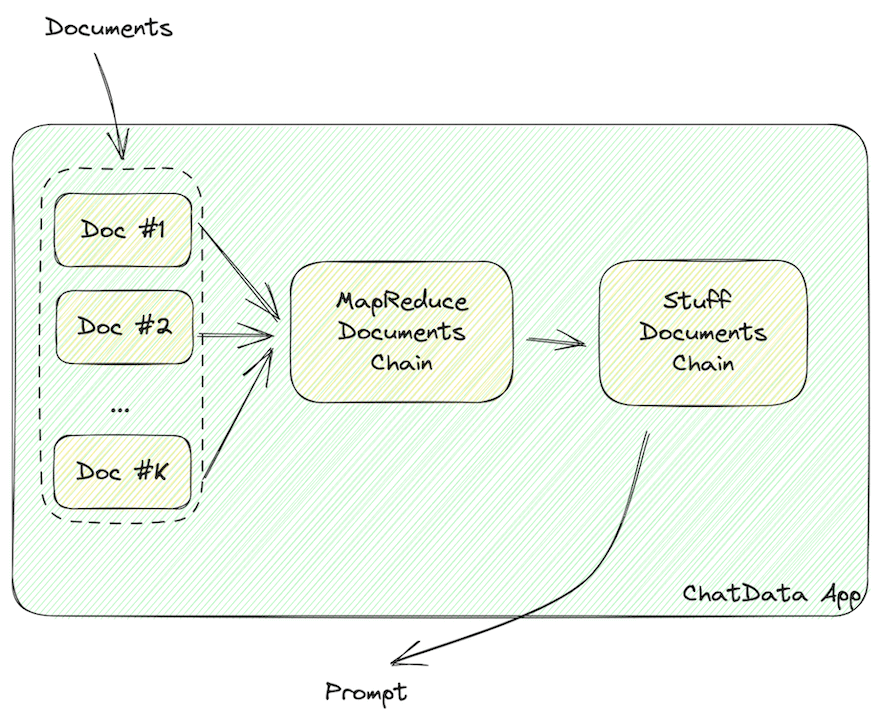
上記の図で示されているように、ベクトルストアから取得したドキュメントデータは、JSONやMarkdownなどのLLMが読み取れる形式の文字列にフォーマットする必要があります。
LangChainでは、次のチェーンを使用してこれらのLLMが読み取れるドキュメントを構築します。
MapReduceDocumentsChainStuffDocumentsChain
MapReduceDocumentChainは、ベクトルストアが返すすべてのドキュメントを収集し、標準形式に正規化します。ドキュメントをプロンプトテンプレートにマッピングし、それらを連結します。StuffDocumentChainは、これらのフォーマットされたドキュメントで作業し、タスクの説明を接頭辞、例を接尾辞として、コンテキストとして挿入します。
ベクトルストアデータをLLMが読み取れるドキュメントにフォーマットするために、アプリのコードに次のコードスニペットを追加します。
chain = RetrievalQAWithSourcesChain.from_llm(
llm=OpenAI(openai_api_key=st.secrets['OPENAI_API_KEY'], temperature=0.
retriever=retriever,
return_source_documents=True,)
# チェーンを実行する
これらのコンポーネントを使用すると、スケーラブルなベクトルストアでの検索とユーザーの質問に回答することができます。
自分で試してみましょう!
ret = st.session_state.chain(st.session_state.query, callbacks=[callback])
# You can find the answer from LLM in the field `answer`
st.markdown(f"### Answer from LLM\n{ret['answer']}\n### References")
# and source documents in `sources` and `source_documents`
docs = ret['source_documents']
レスポンシブではありませんか?
# コールバックを追加する
チェーンは問題ありませんが、クレームがあるかもしれません:もっと速くなければなりません!
はい、チェーンは遅くなります。フィルタリングされたベクトルクエリ(LLMの呼び出し)、ベクトルストアからのデータの取得、LLMへの問い合わせ(別のLLMの呼び出し)を構築するため、合計実行時間は約10〜20秒になります。
心配しないでください。LangChainには、アプリの応答性を向上させるために使用できるCallbacks (opens new window)があります。この例では、いくつかのコールバック関数を追加して進行状況バーを更新しました。
class ChatArXivAskCallBackHandler(StreamlitCallbackHandler):
def __init__(self) -> None:
# You will have a progress bar when this callback is initialized
self.progress_bar = st.progress(value=0.0, text='Searching DB...')
self.status_bar = st.empty()
self.prog_value = 0.0
# You can use chain names to control the progress
self.prog_map = {
'langchain.chains.qa_with_sources.retrieval.RetrievalQAWithSourcesChain': 0.2,
'langchain.chains.combine_documents.map_reduce.MapReduceDocumentsChain': 0.4,
'langchain.chains.combine_documents.stuff.StuffDocumentsChain': 0.8
}
def on_llm_start(self, serialized, prompts, **kwargs) -> None:
pass
def on_text(self, text: str, **kwargs) -> None:
pass
def on_chain_start(self, serialized, inputs, **kwargs) -> None:
# the name is in list, so you can join them in strings.
cid = '.'.join(serialized['id'])
if cid != 'langchain.chains.llm.LLMChain':
self.progress_bar.progress(value=self.prog_map[cid], text=f'Running Chain `{cid}`...')
self.prog_value = self.prog_map[cid]
else:
self.prog_value += 0.1
self.progress_bar.progress(value=self.prog_value, text=f'Running Chain `{cid}`...')
def on_chain_end(self, outputs, **kwargs) -> None:
pass
これで、アプリには私たちのようなきれいな進行状況バーが表示されます。

# まとめ
これがLangChainを使用してLLMアプリを構築する方法です!
今日は、MyScale VectorStoreとチャットするシンプルなLLMアプリの構築方法の概要を説明し、クエリパイプラインでチェーンを使用する方法について説明しました。
この記事が、LLMベースのアプリのアーキテクチャをゼロから設計する際に役立つことを願っています。
Discordサーバー (opens new window)でもお手伝いできます。ベクトルデータベース、LLMアプリ、その他の素晴らしいものについてのお手伝いをいたします。また、当社のオープンデータベースを使用して独自のアプリを構築することも歓迎します!この自己クエリリトリーバーを使用して、MyScaleでより素晴らしいアプリを作成できると信じています!Happy Coding!
次の記事でお会いしましょう!