
# Introducción a MyScale
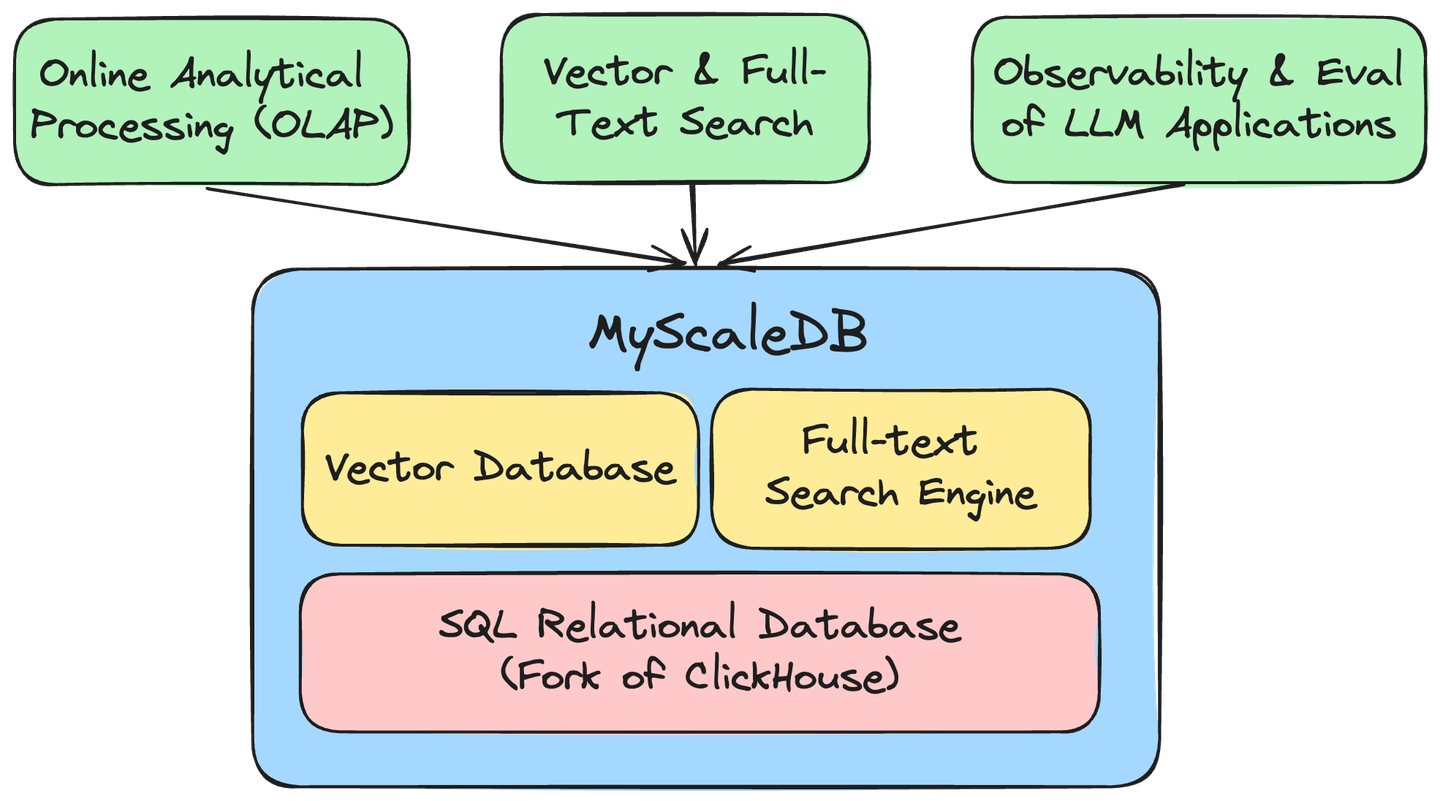
MyScale es una base de datos basada en la nube optimizada para aplicaciones y soluciones de IA, construida sobre la base de datos de código abierto ClickHouse, lo que nos permite gestionar de manera efectiva grandes volúmenes de datos estructurados y de vectores para el desarrollo de aplicaciones robustas de IA. Algunos de los beneficios más significativos de usar MyScale incluyen:
- Diseñado para aplicaciones de IA: Gestiona y admite el procesamiento analítico de datos estructurados y vectorizados en una sola plataforma.
- Diseñado para el rendimiento: Arquitectura de base de datos OLAP de vanguardia para realizar operaciones en datos vectorizados a velocidades increíbles.
- Diseñado para la accesibilidad universal: SQL es el único lenguaje de programación necesario para interactuar con MyScale.
En comparación con las API personalizadas de otros productos/plataformas, MyScale es más fácil de usar; por lo tanto, es adecuado para una gran comunidad de programadores. MyScale elimina la necesidad de múltiples productos costosos de almacenamiento de datos que requieren diferentes lenguajes de consulta con su soporte rentable para la gestión de datos, escalabilidad lineal sobresaliente y soporte de SQL estándar. En una sola interfaz, una consulta SQL puede aprovechar simultáneamente y rápidamente diferentes modalidades de datos para manejar demandas complejas de IA que de otro modo requerirían más pasos y tiempo.
El motor vectorial propietario MSTG de MyScale aprovecha los SSD NVMe para aumentar la densidad de datos por un factor de 10. Este avance permite a MyScale superar incluso a las bases de datos vectoriales más especializadas (opens new window) en un 4x a 10x tanto en rendimiento como en eficiencia de costos. La inclusión de un índice de búsqueda de texto completo (FTS) integra sin problemas capacidades de búsqueda de texto de alto rendimiento, posicionando a MyScale como una actualización eficiente a ElasticSearch (opens new window). Además, MyScale Telemetry (opens new window) ofrece una observabilidad integral para los sistemas LLM, asegurando una monitorización sin problemas y una depuración eficiente.
Al integrar las funcionalidades de una base de datos SQL/almacén de datos, una base de datos vectorial y un motor de búsqueda de texto completo en un solo sistema eficiente, MyScale reduce significativamente los costos de infraestructura y mantenimiento. Esta unificación no solo facilita consultas y análisis de datos conjuntos, sino que también establece una base de datos robusta y versátil esencial para todas las aplicaciones de IA.
# Conceptos clave
MyScale es capaz de realizar consultas rápidas y precisas en diferentes modalidades de datos basándose en los siguientes conceptos clave.
# Métricas de similitud
Existen dos enfoques diferentes para medir la similitud semántica entre dos objetos de datos:
- Unimodal (imagen-imagen o texto-texto): La similitud unimodal mide la similitud semántica entre objetos del mismo tipo de datos.
- Multimodal (imagen-texto): La similitud multimodal mide la similitud semántica entre objetos de diferentes tipos de datos.
Las similitudes semánticas entre dos objetos de datos pueden representarse mediante una puntuación conocida como métrica de similitud. Elegir una buena métrica de similitud para representar las similitudes semánticas en una gran base de datos de objetos es vital para el rendimiento de la clasificación y agrupación de datos en MyScale.
Elegir una buena métrica de similitud para representar las similitudes semánticas en una gran base de datos de objetos es esencial para el rendimiento de la clasificación y agrupación de datos en MyScale. Tres de las métricas más populares incluyen:
- Distancia euclidiana (L2): L2 se utiliza comúnmente en aplicaciones de visión por computadora (CV).
- Producto interno (IP): IP se utiliza principalmente en aplicaciones de procesamiento de lenguaje natural (NLP).
- Similitud del coseno: A diferencia de IP, que considera la "magnitud" y los "ángulos" representados como vectores entre dos objetos, la similitud del coseno solo compara las diferencias en los "ángulos" en datos normalizados.
# Algoritmos de búsqueda
Un vector de incrustación (o vector) es una representación numérica de un objeto, concepto o entidad en un espacio multidimensional. Se utiliza frecuentemente para representar textos de procesamiento de lenguaje natural (NLP), datos de sensores de IoT, fotos de redes sociales, estructuras biológicas y químicas u otros objetos de datos de una manera que captura sus relaciones semánticas e información contextual adicional.
Las incrustaciones están diseñadas para capturar características o características significativas de los datos en un espacio de menor dimensión, lo que facilita que los algoritmos de aprendizaje automático procesen y analicen los datos.
TIP
Las técnicas modernas de incrustación se utilizan para convertir datos no estructurados en vectores, transformando datos de alta dimensión en una forma más compacta y estructurada.
Para comparar la similitud semántica entre dos objetos, se proporciona a la base de datos de MyScale un vector de consulta. MyScale utiliza luego algoritmos de búsqueda como el vecino más cercano aproximado (ANN) para devolver rápidamente y con precisión una lista de vectores similares al vector de consulta.
# Uso de SQL con MyScale
A diferencia de las bases de datos vectoriales propietarias como Pinecone, Milvus, Qdrant y Weaviate, MyScale se basa en la base de datos de código abierto compatible con SQL, ClickHouse. Hay varias razones para esto, que incluyen:
- Podemos proporcionar a nuestros usuarios una base de datos con muchas funciones aprovechando el código base y el ecosistema maduro de ClickHouse.
- SQL se utiliza ampliamente para gestionar bases de datos relacionales. Con el soporte de SQL de MyScale, los desarrolladores y analistas de datos pueden aprovechar sus conocimientos y habilidades existentes, lo que facilita la integración y el uso.
- SQL admite una amplia gama de funciones de manipulación, consulta e informes de datos. Por lo tanto, como MyScale es totalmente compatible con SQL, los usuarios pueden realizar consultas complejas y analizar datos de muchas formas diferentes.
- Como MyScale se basa en ClickHouse, proporciona un rendimiento rápido y escalable no solo para la búsqueda de vectores, sino también para la búsqueda de vectores filtrados y consultas complejas que combinan SQL y vectores, como unir los resultados de búsqueda de vectores con otra tabla.
# ¿Por qué es esto importante?
A medida que los datos complejos crecen de manera exponencial, se necesitan soluciones preparadas para el futuro que puedan manejar nuevas modalidades de datos, tamaños de bases de datos y desafíos para encontrar respuestas a consultas. Si bien esto es importante, no debe ser a expensas del rendimiento informático y la falta de integración entre diferentes modalidades de datos.
Además de los formatos de datos tradicionales, MyScale también puede manejar modalidades de datos futuras. En MyScale, combinar datos estructurados tradicionales con resultados de búsqueda de vectores en SQL es un enfoque poderoso para abordar preguntas complejas relacionadas con la IA y mantener el rendimiento.
Sigue leyendo para descubrir cómo funciona MyScale y cómo puedes integrarlo en tu solución.