
# Guía de inicio rápido
![]()
![]()
Esta guía te mostrará cómo lanzar un clúster, importar datos y ejecutar consultas SQL en unos simples pasos. Puedes encontrar más información sobre otras herramientas para desarrolladores, como el Cliente de Python, en la sección de Herramientas para Desarrolladores.
# Cómo Lanzar Tu Primer Clúster
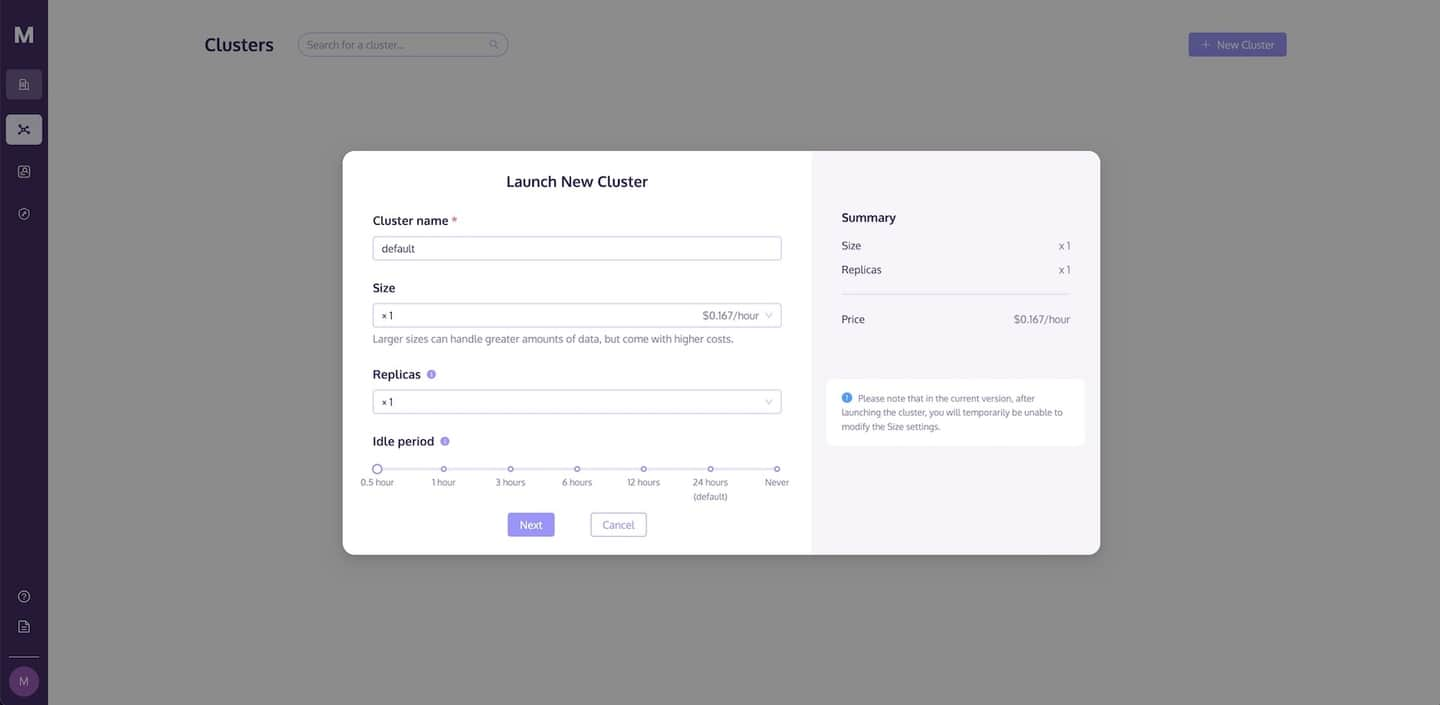
Antes de realizar cualquier operación de datos, necesitas lanzar un clúster. La página de Clústers te permite crear un clúster y configurar los recursos de cómputo y almacenamiento según tus necesidades.
Sigue estos pasos para lanzar un nuevo clúster:
- Ve a la página de Clústers y haz clic en el botón +Nuevo Clúster para lanzar un nuevo clúster.
- Nombra tu clúster.
- Haz clic en Lanzar para ejecutar el clúster.
TIP
La capa de desarrollo de MyScale está limitada a la configuración predeterminada y no admite réplicas múltiples. Consulta la sección Cambiar tu Plan de Facturación y actualiza al plan estándar para obtener una configuración más potente.
# Configuración del Entorno
Tienes la opción de conectarte a una base de datos de MyScale utilizando una de las siguientes herramientas para desarrolladores:
Sin embargo, vamos a utilizar Python para comenzar.
# Usando Python
Antes de comenzar con Python, necesitas instalar el cliente de ClickHouse (opens new window), como se describe en el siguiente script de shell:
pip install clickhouse-connect
Una vez que el cliente de ClickHouse se haya instalado correctamente, el siguiente paso es conectarse a tu clúster de MyScale desde una aplicación de Python proporcionando los siguientes detalles:
- Host del clúster
- Nombre de usuario
- Contraseña
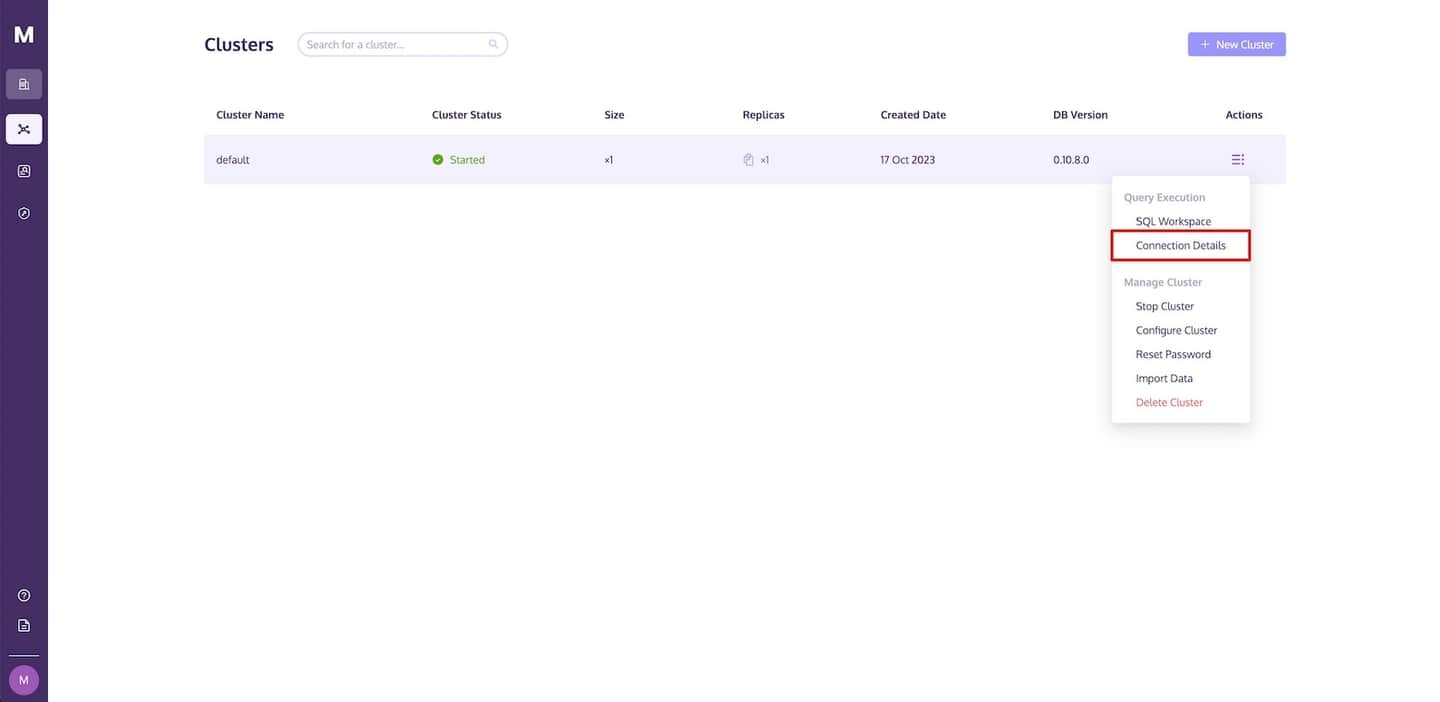
Para encontrar estos detalles, ve a la página de Clústers de MyScale, haz clic en el enlace desplegable Acción y selecciona Detalles de Conexión.
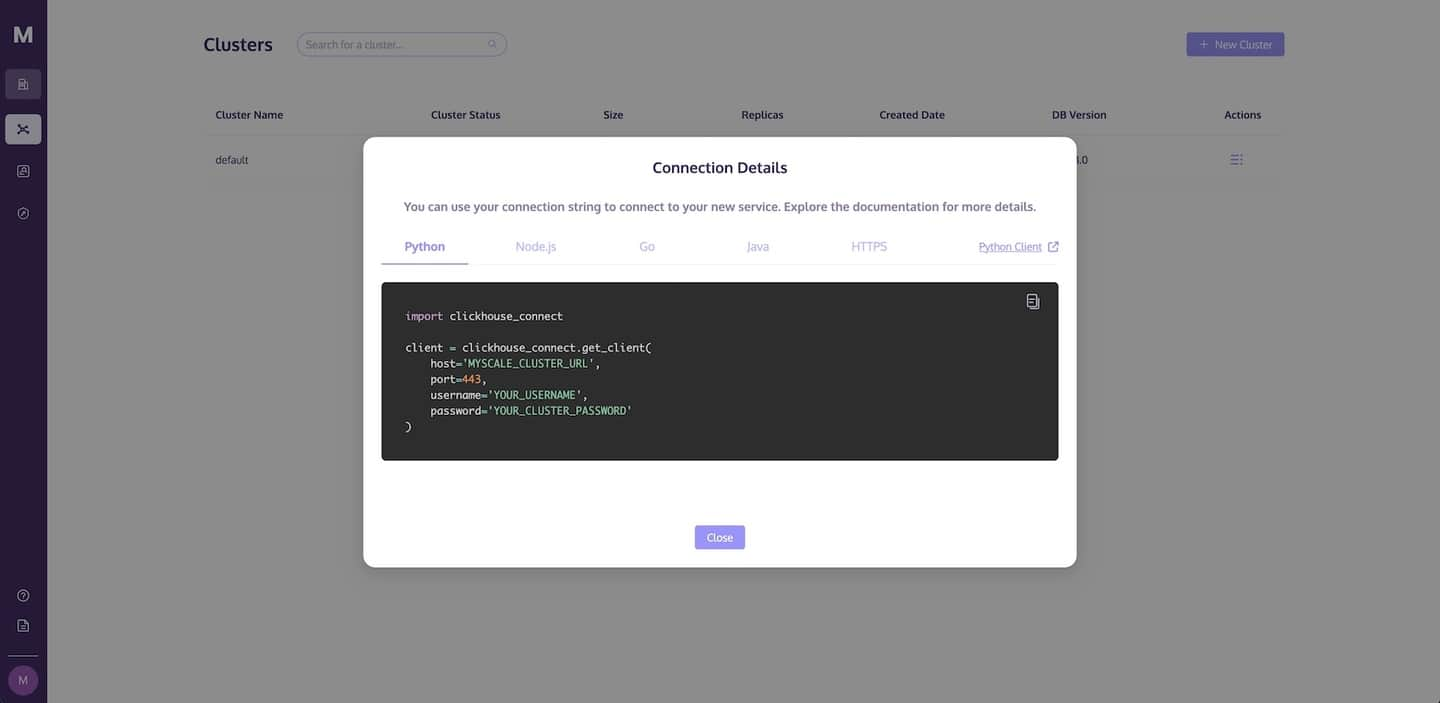
Como se muestra en la siguiente imagen, se mostrará un cuadro de diálogo Detalles de Conexión con el código necesario para acceder a MyScale. Haz clic en el icono de copiar para copiar el código correspondiente y pégalo en tu aplicación de Python.
TIP
Consulta Detalles de Conexión para obtener más información sobre cómo conectarte a tu clúster de MyScale.
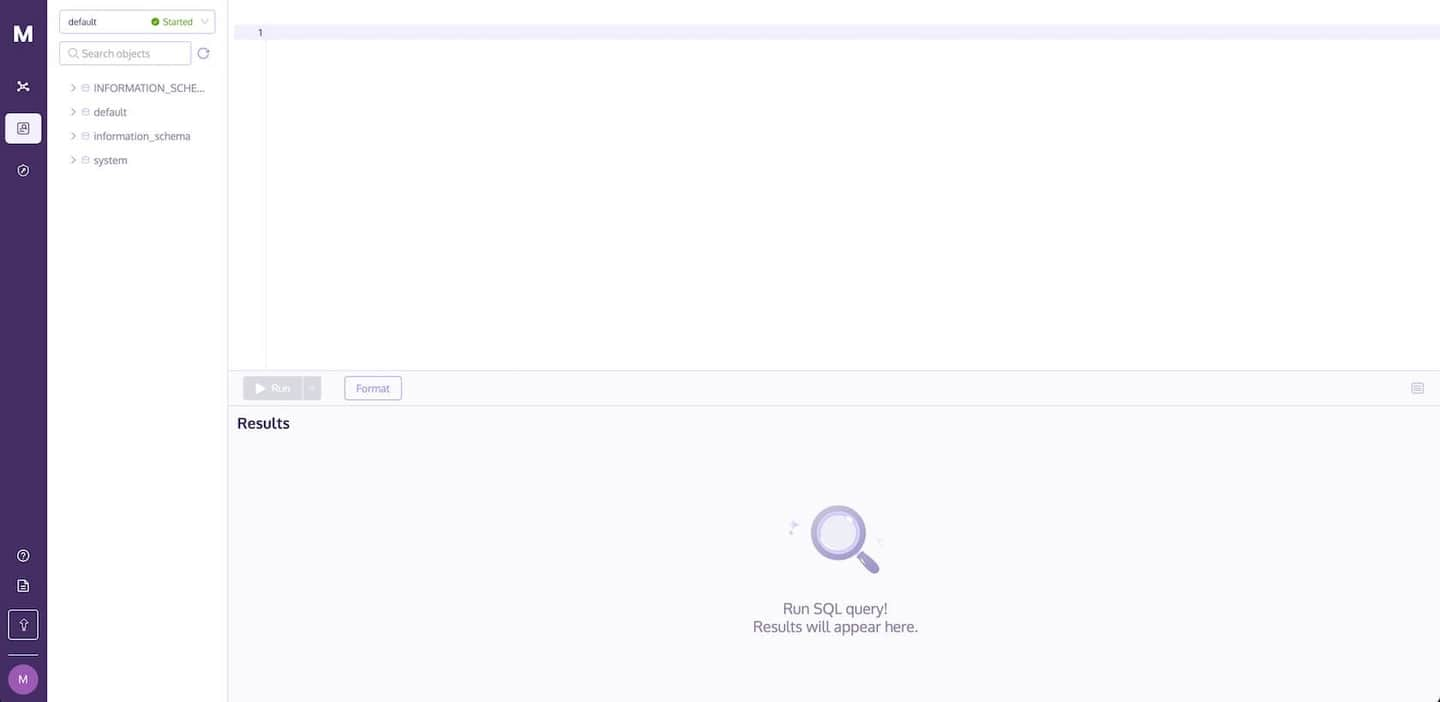
# Usando la Consola de MyScale
Para utilizar la consola de MyScale para importar datos en tu base de datos y ejecutar consultas, ve a la página de Espacio de Trabajo SQL. Tu clúster se seleccionará automáticamente, como se muestra a continuación:
# Cómo Importar Datos en la Base de Datos
Sigue estos pasos para importar datos en MyScale:
# Crear una Tabla
Crear una tabla de base de datos en MyScale antes de importar cualquier dato es obligatorio.
TIP
Para obtener más información, ve al documento que describe cómo Crear una Base de Datos y cómo Crear una Tabla en la sección de Referencia SQL.
Utilizando los siguientes ejemplos de código, escribamos una declaración SQL (tanto en Python como en SQL) para crear una nueva tabla llamada default.myscale_categorical_search.
- Python
- SQL
# Crear una tabla con vectores de 128 dimensiones.
client.command("""
CREATE TABLE default.myscale_categorical_search
(
id UInt32,
data Array(Float32),
CONSTRAINT check_length CHECK length(data) = 128,
date Date,
label Enum8('person' = 1, 'building' = 2, 'animal' = 3)
)
ORDER BY id""")
# Insertar Datos en la Tabla
TIP
MyScale admite la importación de datos desde Amazon S3 y otros servicios en la nube utilizando API compatibles con S3. Consulta la función de tabla s3 para obtener más información sobre cómo importar datos desde Amazon S3.
Como se describe en los siguientes fragmentos de código, usemos SQL para importar datos en la tabla default.myscale_categorical_search.
Los formatos de archivo admitidos incluyen:
CSV(opens new window)CSVWithNames(opens new window)JSONEachRow(opens new window)Parquet(opens new window)
TIP
Consulta Formatos para Datos de Entrada y Salida (opens new window) para obtener una descripción detallada de todos los formatos admitidos.
- Python
- SQL
client.command("""
INSERT INTO default.myscale_categorical_search
SELECT * FROM s3(
'https://d3lhz231q7ogjd.cloudfront.net/sample-datasets/quick-start/categorical-search.csv',
'CSVWithNames',
'id UInt32, data Array(Float32), date Date, label Enum8(''person'' = 1, ''building'' = 2, ''animal'' = 3)'
)""")
# Construir un Índice Vectorial
Además de crear índices tradicionales en datos estructurados, también puedes crear un Índice Vectorial en MyScale para incrustaciones vectoriales. Sigue esta guía paso a paso para ver cómo:
# Crear un Índice Vectorial MSTG
Como muestran los siguientes fragmentos de código, el primer paso es crear un índice vectorial MSTG, un índice vectorial que utiliza nuestro algoritmo propietario, MSTG.
- Python
- SQL
client.command("""
ALTER TABLE default.myscale_categorical_search
ADD VECTOR INDEX categorical_vector_idx data
TYPE MSTG
""")
TIP
El tiempo de construcción del índice depende del tamaño de la importación de datos.
# Verificar el estado de construcción del índice vectorial
Los siguientes fragmentos de código describen cómo usar SQL para verificar el estado de construcción del índice vectorial.
- Python
- SQL
# Consultar la tabla del sistema 'vector_indices' para verificar el estado de la creación del índice.
get_index_status="SELECT status FROM system.vector_indices WHERE table='myscale_categorical_search'"
# Imprimir el estado de la creación del índice. El estado será 'Built' si el índice se creó correctamente.
print(f"El estado de construcción del índice es {client.command(get_index_status)}")
La salida se muestra en los siguientes ejemplos:
- Python
- SQL
El estado de construcción del índice es Built
TIP
Consulte la Búsqueda vectorial para obtener más información sobre los índices vectoriales.
# Ejecución de consultas SQL
Una vez que haya importado datos en una tabla MyScale y haya construido un índice vectorial, puede consultar los datos utilizando los siguientes tipos de búsqueda:
TIP
El beneficio más significativo de construir un índice vectorial MSTG es su velocidad de búsqueda extremadamente rápida.
# Búsqueda vectorial
Convencionalmente, se consultan textos o imágenes, como "un coche azul" o imágenes de un coche azul. Sin embargo, MyScale trata todas las consultas como vectores y devuelve una respuesta a la consulta basada en la similitud ("distancia") entre la consulta y los datos existentes en la tabla.
Utilice los siguientes fragmentos de código para recuperar datos utilizando un vector como consulta:
- Python
- SQL
# seleccionar una fila aleatoria de la tabla como objetivo
random_row = client.query("SELECT * FROM default.myscale_categorical_search ORDER BY rand() LIMIT 1")
assert random_row.row_count == 1
target_row_id = random_row.first_item["id"]
target_row_label = random_row.first_item["label"]
target_row_date = random_row.first_item["date"]
target_row_data = random_row.first_item["data"]
print("elemento seleccionado actualmente id={}, etiqueta={}, fecha={}".format(target_row_id, target_row_label, target_row_date))
# Obtener el resultado de la consulta.
result = client.query(f"""
SELECT id, date, label,
distance(data, {target_row_data}) as dist FROM default.myscale_categorical_search ORDER BY dist LIMIT 10
""")
# Iterar a través de las filas del resultado de la consulta e imprimir el 'id', 'date',
# 'label' y distancia para cada fila.
print("Top 10 candidatos:")
for row in result.named_results():
print(row["id"], row["date"], row["label"], row["dist"])
El conjunto de resultados que contiene los diez resultados más similares es el siguiente:
| id | date | label | dist |
|---|---|---|---|
| 0 | 2030-09-26 | person | 0 |
| 2 | 1975-10-07 | animal | 60,088 |
| 395,686 | 1975-05-04 | animal | 70,682 |
| 203,483 | 1982-11-28 | building | 72,585 |
| 597,767 | 2020-09-10 | building | 72,743 |
| 794,777 | 2015-04-03 | person | 74,797 |
| 591,738 | 2008-07-15 | person | 75,256 |
| 209,719 | 1978-06-13 | building | 76,462 |
| 608,767 | 1970-12-19 | building | 79,107 |
| 591,816 | 1995-03-20 | building | 79,390 |
TIP
Estos resultados son incrustaciones vectoriales, que puede utilizar para recuperar los datos originales haciendo referencia al id de los resultados.
# Búsqueda filtrada
No solo podemos consultar datos utilizando una búsqueda vectorial (usando incrustaciones vectoriales), sino que también podemos ejecutar consultas SQL utilizando una combinación de datos estructurados y vectoriales, como se describe en los siguientes fragmentos de código:
- Python
- SQL
# Obtener el resultado de la consulta.
result = client.query(f"""
SELECT id, date, label,
distance(data, {target_row_data}) as dist
FROM default.myscale_categorical_search WHERE toYear(date) >= 2000 AND label = 'animal'
ORDER BY dist LIMIT 10
""")
# Iterar a través de las filas del resultado de la consulta e imprimir el 'id', 'date',
# 'label' y distancia para cada fila.
for row in result.named_results():
print(row["id"], row["date"], row["label"], row["dist"])
El conjunto de resultados que contiene los diez resultados más similares es el siguiente:
| id | date | label | dist |
|---|---|---|---|
| 601,326 | 2001-05-09 | animal | 83,481 |
| 406,181 | 2004-12-18 | animal | 93,655 |
| 13,369 | 2003-01-31 | animal | 95,158 |
| 209,834 | 2031-01-24 | animal | 97,258 |
| 10,216 | 2011-08-02 | animal | 103,297 |
| 605,180 | 2009-04-20 | animal | 103,839 |
| 21,768 | 2021-01-27 | animal | 105,764 |
| 1,988 | 2000-03-02 | animal | 107,305 |
| 598,464 | 2003-01-06 | animal | 109,670 |
| 200,525 | 2024-11-06 | animal | 110,029 |