
# AIGC プロンプト管理
![]()
AIGC(Artificial Intelligence Generated Content)は、多くの人々に個人的なイメージを作成するインスピレーションを与え続けています。
AIGCへのこの成長する関心に応えて、人々はStable DiffusionとLLMs(Large Language Models)を統合するなど、革新的な手法を探求しています。
しかし、まずStable Diffusionとは何でしょうか?
Stable Diffusion (opens new window)は、「テキスト記述に基づいて詳細な画像を生成するために主に使用されるディープラーニングのテキストから画像へのモデル」です。
Stable Diffusionの力を活用することで、視覚的に魅力的な画像を生成することができます。実際には、Stable Diffusionモデルのプロセスが画像をレンダリングする際には、滑らかで一貫性のある詳細な画像が生成されます。
この創造的なプロセスの一環として、強力なLLMs(Large Language Modes)を組み合わせることで、ユーザーはテキストのプロンプトや説明を入力することができ、AIシステムがそれに応じた画像を生成することができます。その結果、人々は自分たちの芸術的なビジョンを実現することができ、AIGCが提供する素晴らしい可能性を示す作品を見ることで満足感を得ることができます。
ただし、最初のテキストのプロンプトや説明を入力することは難しい場合があります。幸いなことに、その問題を解決する方法があります:私たちはMyScaleなどのベクトルデータベースの力を活用することができます。
どのようにしてでしょうか?
成功裏に画像を生成するために使用されたプロンプトの広範なコレクションをMyScaleのベクトルデータベースに保存し、整理することで、インスピレーションを必要とするユーザーや適切なプロンプトを見つけるのに苦労しているユーザーにとって貴重なリソースを提供することができます。適切にキュレーションされたベクトルデータベースを使用することで、意図したスタイルとコンセプトに密接に合致するプロンプトを簡単に見つけ出すことができます。
これにより、創造的なプロセスが簡素化され、アクセス性が向上し、ユーザーはプロンプトの選択においてサポートを受けることができます。ベクトルデータベースを利用することで、ユーザーは初期のプロンプトの課題を乗り越え、自信と明確さを持って画像を生成することができるようになります。
# MyScaleを使用したAIGCプロンプト管理の改善
どこから始めるべきでしょうか?
次のパイプラインを使用して、プロンプトのコレクションを保存して整理するためのベクトルデータベースを作成しましょう。
指定された画像のプロンプトを見つける: 特定の画像に関連するプロンプトテキストを見つけるために、MyScaleを使用して逆検索を行うことができます。画像の特徴を保存されたベクトルと比較することで、おそらくその画像を生成したプロンプトまたはプロンプトを特定することができます。この結果、画像の創造プロセスから学ぶことができます。
特定のスタイルに似た画像を見つける: MyScaleを利用することで、ベクトル表現の比較によって、生成したいスタイルに密接に似た画像を検索することができます。MyScaleデータベースを使用して、価値のある参考資料や画像生成のためのインスピレーションとなるキュレーションされた画像にアクセスすることができます。
一般的なアイデアに対する具体的なプロンプトを取得する: MyScaleを使用することで、ベクトル表現を比較することで、生成したいスタイルに密接に似た画像を検索することができます。MyScaleデータベースは、価値のある参考資料やインスピレーションとなるキュレーションされた画像にアクセスすることができます。
検索とLLMsを使用してプロンプトを改善する: 検索アルゴリズムとLLMsを組み合わせることで、プロンプトの効果を向上させることができます。ベクトルデータベースを検索することで、過去に関連する結果を生成したプロンプトを見つけることができます。既存のプロンプトを改善するだけでなく、これらのプロンプトは出発点として機能します。LLMsを使用して新しいプロンプトのバリエーションを生成したり、既存のプロンプトを洗練させたりすることもできます。これにより、画像生成プロセスを最適化することができます。
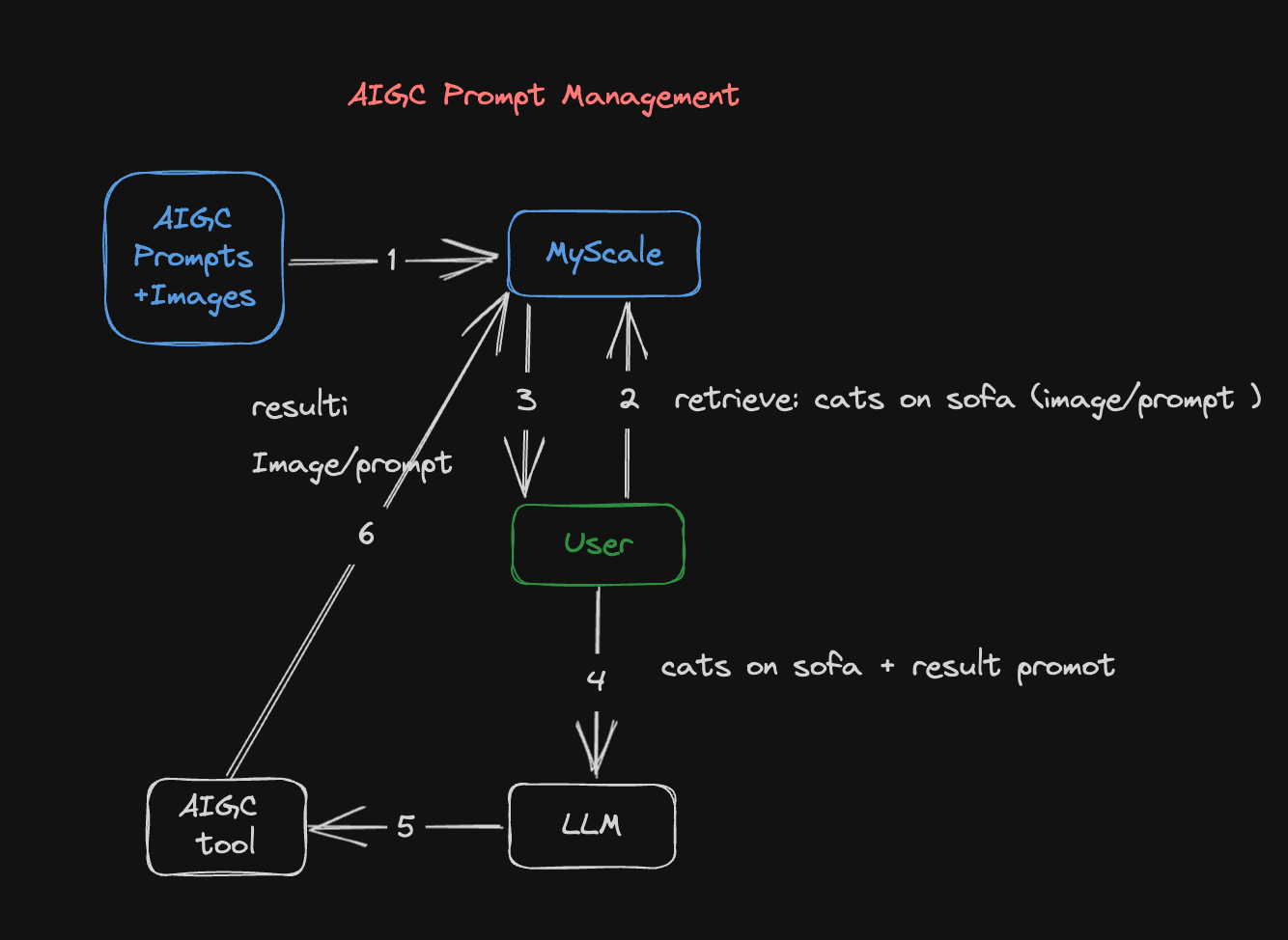
図1: AIGCプロンプト管理パイプライン
この図は、AIGCのプロンプト管理パイプラインが画像を生成する方法を示しています。
画像と関連するプロンプトのデータセットは、埋め込みに変換され、MyScaleデータベースに保存されます。埋め込みは、画像またはプロンプトをベクトル表現に変換することで、後で取得して使用することができます。
2番目のステップは、画像またはプロンプトを使用してMyScaleデータベースを検索することです。既存の画像がある場合は、それをベクトル表現に変換し、データベースの画像ベクトルと比較します。同様に、既存のプロンプトがある場合は、それをベクトル表現に変換し、既存のベクトル化されたプロンプトと比較します。
MyScaleデータベースは、入力された画像またはプロンプトに一致する結果を返します。データベースに送信されたクエリに含まれる画像またはプロンプトに類似した画像またはプロンプトを返します。
データベースから返された画像とプロンプトの結果を参照し、LLMsを使用してプロンプトを改善します。LLMsは、これらの結果を分析し学習することができ、ユニークで最適化されたプロンプトを生成し、期待値と創造的な方向性を洗練するのに役立ちます。
次に、改善されたプロンプトに基づいてStable Diffusionモデルを使用してより正確な画像を生成します。改善されたプロンプトを入力して、Stable Diffusionモデルにフィードすることで、このプロンプトに関連する画像を作成します。
最後に、生成された画像と改善されたプロンプトは、将来の使用のためにMyScaleのデータベースに保存されます。データベース内の画像とプロンプトが継続的に蓄積されることで、将来の検索と創造的な取り組みが可能になります。
# ケーススタディ:画像の生成
このシナリオでは、次のプロンプトに基づいてStable Diffusionモデル (opens new window)を使用して画像を生成します。「ソファで寝ている猫」というプロンプトに基づいて、次の画像が生成されます。

素晴らしいスタートです。しかし、次のワークフローに進むことで、この画像を改善することができます。
# 必要なものをインストールする
最初に、以下の前提条件(およびstreamlit、pandas、lmdb、torch)をインストールするために、このセクションの最後にあるCLIコマンドを実行します。
transformers:テキストと画像の埋め込みを作成するためのCLIPモデルtqdm:美しい進捗バーclickhouse-connect:MyScaleデータベースクライアント
python3 -m pip install transformers tqdm clickhouse-connect streamlit pandas lmdb torch
# データの準備
まず、Kaggleから900k Diffusion Prompts Dataset (opens new window)を使用します。このデータセットには、900,000のStable Diffusionプロンプトとそれに対応する画像のURLのペアが含まれています。各ペアには、Stable Diffusionモデルのプロンプトと関連する画像のURLが含まれています。
例えば:
| id | prompt | url | width | height | source_site |
|---|---|---|---|---|---|
| 00000d0e-45cb-47b6-9f72-6a481e940d78 | man waking up, dark and still room, cinematic ... | Image_Url | 512 | 512 | stablediffusionweb.com (opens new window) |
この例では、データセットは次の6つの列で構成されています:
- id: 各プロンプトと画像のペアの一意の識別子
- prompt: 画像のペアのプロンプト
- url: プロンプトに関連する画像へのURL
- width: 画像の幅
- height: 画像の高さ
- source_site: 画像のラベル
以下の画像は、この画像ペアにリンクされた実際の画像です。Image_Urlをクリックすることで、ソースサイトから取得されます。
# MyScaleデータベースのテーブルを作成する
MyScaleのオンラインコンソールを使用しない限り、MyScaleのデータベースバックエンドに接続する必要があります。
MyScaleデータベースバックエンドに接続するためのPythonクライアント (opens new window)の設定方法については、詳細なガイドを参照してください。
SQL(Structured Query Language)に精通している場合、MyScaleを使用する際には作業が容易になります。MyScaleは、構造化されたSQLクエリとベクトル検索を組み合わせており、データベーステーブルの作成を含むほとんどのデータベース操作が通常のデータベーステーブルの作成とほぼ同じです。
次のSQLステートメントは、SQLでベクトルテーブルを作成する方法を示しています。
CREATE TABLE IF NOT EXISTS Prompt_text_900k(
id String,
prompt String,
url String,
width UInt64,
height UInt64,
source_site String,
prompt_vector Array(Float32),
CONSTRAINT vec_len CHECK length(prompt_vector) = 512
) ENGINE = MergeTree ORDER BY id;
# データを抽出し、データセットを作成する
CLIP (opens new window)は、テキストと画像を一致させることで、高性能な検索を可能にするためのモデルです。CLIPは、画像内のオブジェクトやシーンを認識し、テキストを分析することができます。これにより、高い精度と速度で画像とテキストを一致させることができ、複数のモードでの高速かつ正確な検索が可能になります。
以下は、その例です。
import torchimport clipfrom PIL import Image
# CLIPモデルをロードする
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 画像をロードして前処理する
# テキストをエンコードする
text = "Your text here"
text_input = clip.tokenize([text]).to(device)
with torch.no_grad():
text_features = model.encode_text(text_input)
# 画像とテキストの特徴を表示する
print("Image features shape:", image_features.shape)
print("Text features shape:", text_features.shape)
# データをMyScaleにアップロードする
次に、埋め込みをMyScaleにアップロードし、ベクトルインデックスを作成します。以下のPythonの抜粋に示すようにします。
# データセットからデータをアップロードする
client.insert("Prompt_text_900k",
data_text.to_records(index=False).tolist(),
column_names=data_image.columns.tolist())
# コサインを使用してベクトルインデックスを作成する
client.command("""
ALTER TABLE Prompt_text_900k
ADD VECTOR INDEX prompt_vector_index feature
TYPE MSTG
('metric_type=Cosine')
""")
# MyScaleデータベースを検索する
ユーザーがプロンプトを入力すると、それをベクトルに変換し、データベースをクエリして上位n個のプロンプトとそれに対応する画像を返します。以下の手順を使用して、MyScaleデータベースを検索します。
最初のステップは、プロンプト(質問)をベクトルに変換することです。次のコードスニペットに示すように行います。
question = 'A cat is sleeping on the sofa' emb_query = retriever.encode(question).tolist()2番目のステップは、データセットを検索し、上位no個のプロンプト(テキスト)とそれに対応する画像を返すクエリを実行することです。次のコードスニペットに示すように行います。
top_k = 2 results = client.query(f""" SELECT prompt, url, distance(prompt_vector, {emb_query}) as dist FROM Prompt_text_900k ORDER BY dist LIMIT {top_k} """) summaries = {'prompt': [], 'url': []} for res in results.named_results(): summaries['prompt'].append(res["prompt"]) summaries['url'].append(res["url"])
クエリの結果は、次のコードスニペットに示されています。
{'prompt':['`two cute calico cats sleeping inside a cozy home in the evening, two multi - colored calico cats`','`two cats sleeping by the window Chinese new year digital art painting by makoto shinkai`'],
'url': ['`https://image.lexica.art/full_jpg/c6fc8242-86b6-4a2c-adee-3053bb345147`','https://image.lexica.art/full_jpg/06c4451c-ce40-4926-9ec7-0381f3dcc028']}
これらのURLは、次の画像を指しています。


# 新しい画像を生成する
GPT4のAPIを使用することで、このクエリから返されたデータに基づいてGPT4で新しいプロンプトを作成することができます。次のコードスニペットに示すように行います。
system_message = f"""
Please provide a more native-sounding rewrite of the user-input
image generation prompt based on the following description
{summaries}
"""
次の画像は、これらの新しいプロンプトを使用して生成されます。


画像の検索も同様のパイプラインで行うことができます。
# 結論
個人のイメージがAIGCトレンドの中心にあります。Stable DiffusionとLLMsを使用することで、視覚的に魅力的なコンテンツを作成することができます。MyScaleを使用することで、この記事全体で説明したような包括的なベクトルデータベースを使用して、適切なプロンプトを見つけることができます。ユーザーは、Stable DiffusionとLLMsを使用したMyScaleを介してAIGCと対話し、課題を乗り越え、創造性を洗練させることができます。これにより、ユニークなAI生成コンテンツが生まれます。