
# AIGC 提示管理
![]()
AIGC(人工智能生成内容)激发并持续激发着许多人创作个人形象,以反映他们独特的品味和偏好。
针对这种对AIGC的日益迷恋,人们正在探索创新技术,如集成稳定扩散和LLM(大型语言模型)。
但首先,什么是稳定扩散?
稳定扩散 (opens new window) 是一种“深度学习,文本到图像模型,主要用于根据文本描述生成详细图像”。
通过利用稳定扩散的力量,您可以生成视觉上引人注目的图像。在实践中,稳定扩散模型的处理过程中,图像平滑一致,产生详细的图像。
作为这个创作过程的一部分,将强大的LLM(大型语言模型)与之结合,使用户能够输入文本提示或描述,使AI系统能够根据他们的审美偏好生成相应的图像。结果,人们能够赋予他们的艺术愿景以生命,展示AIGC提供的卓越可能性,从而产生一种满足感。
然而,输入初始文本提示或描述可能具有挑战性。幸运的是,我们可以利用矢量数据库(如MyScale)的强大功能来克服这个障碍。
如何做到?
我们可以在MyScale矢量数据库中存储和组织已成功用于生成图像的广泛提示集合,为需要灵感或在寻找合适提示时遇到困难的用户提供宝贵的资源。一个经过精心策划的矢量数据库可以轻松找到并检索与图像预期风格和概念密切相关的提示。
这反过来简化了创作过程,使其更易于访问,并帮助用户进行提示选择。最终利用矢量数据库使用户能够克服初始提示的挑战,并以自信和清晰地开始生成图像。
# 利用MyScale改进AIGC提示管理
我们从哪里开始?
让我们从使用以下流程创建矢量数据库来存储和组织我们的提示集合开始:
发现给定图像的提示: 要找到与特定图像相关联的提示文本,我们可以使用MyScale进行反向搜索。通过将图像的特征与存储的矢量进行比较,我们可以确定可能生成图像的提示或提示。我们可以从中了解到图像背后的创作过程。
查找与特定风格相似的图像: 利用MyScale,我们可以通过将所需风格的矢量表示与数据库中的矢量表示进行比较,搜索与我们希望生成的风格密切相似的图像。我们可以使用MyScale数据库访问精选图像,这些图像可以作为图像生成的有价值的参考和灵感。
获取一般想法的具体提示: 使用MyScale,我们可以通过将其矢量表示与数据库中的矢量表示进行比较,搜索与我们希望生成的风格密切相似的图像。MyScale数据库提供了作为有价值的参考和灵感的精选图像。
使用搜索和LLM改进提示: 结合搜索算法和LLM可以提高我们的提示的效果。搜索矢量数据库可以找到过去产生相关结果的提示。除了改进现有提示外,这些提示还可以作为起点。我们还可以使用LLM生成新的提示变体或改进现有提示,优化图像生成过程。
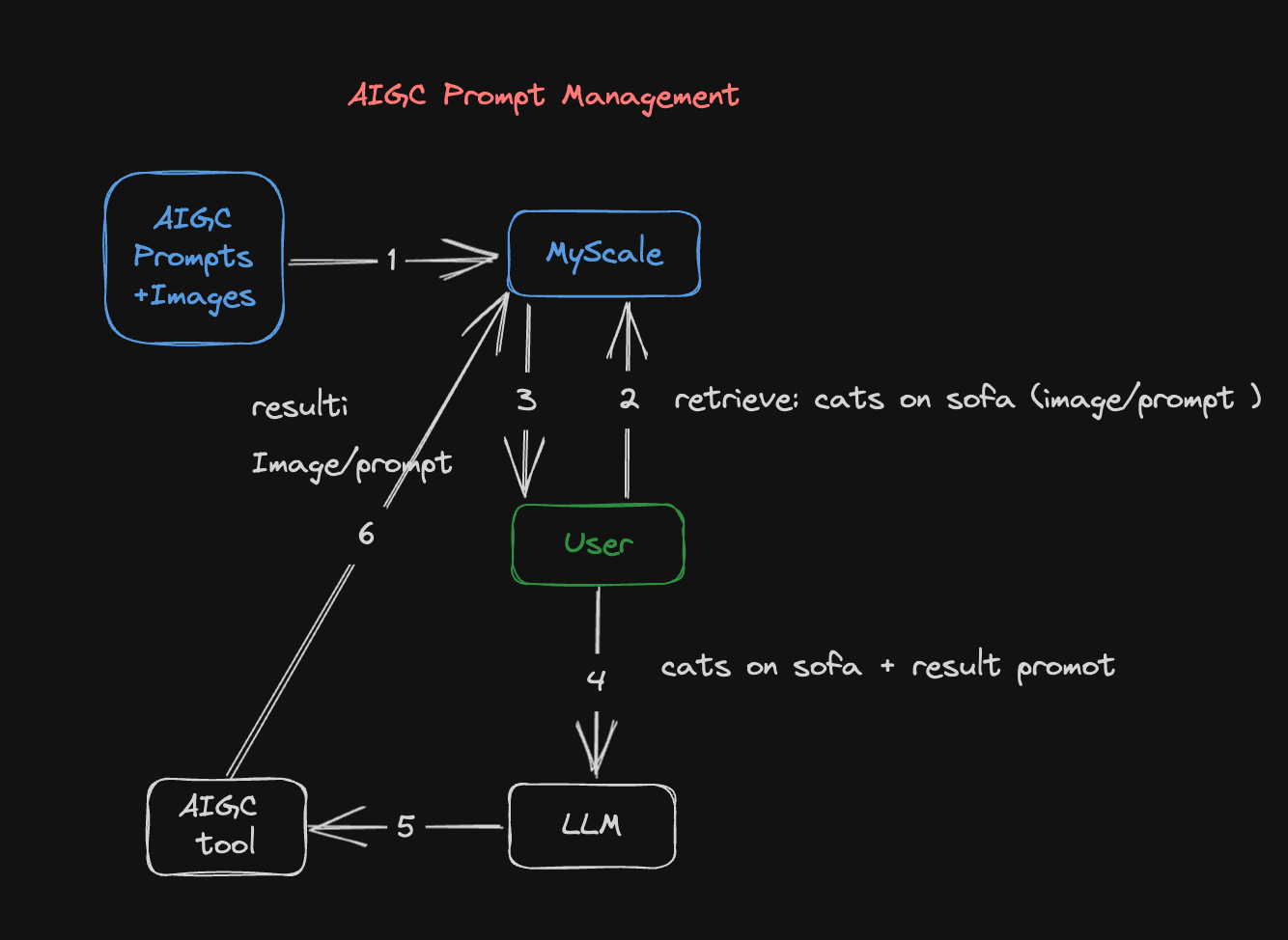
图1: AIGC提示管理流程
该图解说明了AIGC的提示管理流程如何生成图像:
包含图像及其相关提示的数据集被转换为嵌入,并存储在MyScale数据库中。嵌入涉及将图像或提示转换为矢量表示,使其可以在此过程中检索和使用。
第二步是使用图像或提示搜索MyScale数据库。如果您有现有图像,可以将其转换为矢量表示,并将其与数据库中的图像矢量进行比较。同样,如果您有现有提示,可以将其转换为矢量表示,并与现有的矢量化提示进行比较。
MyScale数据库返回与输入图像或提示匹配的结果。一旦将包含图像或提示的查询提交给数据库,它将返回存储在其中的相似图像或提示。
您可以参考从数据库返回的图像和提示结果,并使用LLM改进提示。LLM可以分析和学习这些结果,生成独特且优化的提示,并帮助您完善期望和创意方向。
然后使用稳定扩散模型根据改进的提示生成更准确的图像。在实践中,改进提示后,将其输入稳定扩散模型,以创建与此提示相关的图像。
最后,生成的图像和改进的提示存储在MyScale的数据库中,以供将来使用。随着数据库中图像和提示的不断积累,未来的搜索和创作工作变得可能。
# 案例研究:生成图像
在这种情况下,我们使用稳定扩散模型 (opens new window)根据以下提示生成图像:“一只猫正在沙发上睡觉。”
生成的图像如下:

一个很好的开始。但是我们可以通过以下工作流程改进这个图像:
# 安装先决条件
第一步是通过运行本节底部的CLI命令安装以下先决条件(以及streamlit,pandas,lmdb和torch):
transformers:用于创建文本和图像嵌入的CLIP模型tqdm:美观的进度条clickhouse-connect:MyScale数据库客户端
python3 -m pip install transformers tqdm clickhouse-connect streamlit pandas lmdb torch
# 准备数据
让我们从Kaggle上的900k扩散提示数据集 (opens new window)开始。该数据集包含900,000个稳定扩散提示及其对应的图像URL对。每个对包括稳定扩散模型的提示和相关的图像URL。
例如:
| id | prompt | url | width | height | source_site |
|---|---|---|---|---|---|
| 00000d0e-45cb-47b6-9f72-6a481e940d78 | man waking up, dark and still room, cinematic ... | Image_Url | 512 | 512 | stablediffusionweb.com (opens new window) |
如此示例所示,数据集包含以下六列:
- id: 每个提示和图像对的唯一标识符
- prompt: 图像对的提示
- url: 指向提示关联图像的URL
- width: 图像的宽度
- height: 图像的高度
- source_site: 图像的标签
下面的图像是与此图像对关联的实际图像。通过点击Image_Url获取。
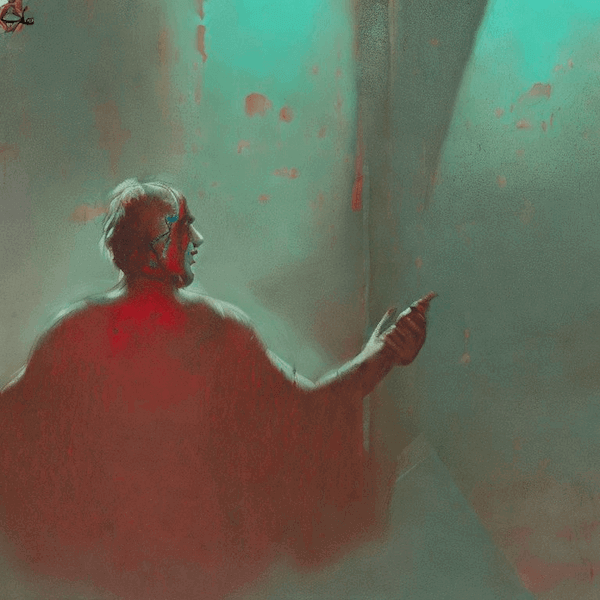
# 创建MyScale数据库表
除非您使用MyScale的在线控制台,否则您需要连接到我们的数据库后端以创建MyScale表。
请参阅我们的详细指南,了解如何设置Python客户端 (opens new window)以连接到MyScale数据库后端。
如果您熟悉SQL(结构化查询语言),那么使用MyScale将更加容易。MyScale将结构化的SQL查询与矢量搜索相结合,包括创建数据库表。换句话说,创建矢量数据库表与创建传统数据库表几乎相同。
以下SQL语句描述了如何在SQL中创建矢量表:
CREATE TABLE IF NOT EXISTS Prompt_text_900k(
id String,
prompt String,
url String,
width UInt64,
height UInt64,
source_site String,
prompt_vector Array(Float32),
CONSTRAINT vec_len CHECK length(prompt_vector) = 512
) ENGINE = MergeTree ORDER BY id;
# 提取文本和图像对,创建数据集
CLIP (opens new window)可以匹配文本和图像,以实现跨模态的高性能检索。CLIP可以学习识别图像中的对象和场景,并使用文本分析内容。这使得它能够以高准确性和速度匹配图像和文本,实现快速准确的跨模态搜索。
以下是一个示例:
import torchimport clipfrom PIL import Image
# Load the CLIP model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# Load and preprocess the image
# Encode the text
text = "Your text here"
text_input = clip.tokenize([text]).to(device)
with torch.no_grad():
text_features = model.encode_text(text_input)
# Print the image and text features
print("Image features shape:", image_features.shape)
print("Text features shape:", text_features.shape)
# 将数据上传到MyScale
接下来,将嵌入上传到MyScale并创建矢量索引,如以下Python示例所示:
# upload data from datasets
client.insert("Prompt_text_900k",
data_text.to_records(index=False).tolist(),
column_names=data_image.columns.tolist())
# create vector index with cosine
client.command("""
ALTER TABLE Prompt_text_900k
ADD VECTOR INDEX prompt_vector_index feature
TYPE MSTG
('metric_type=Cosine')
""")
# 搜索MyScale数据库
当用户输入提示时,我们将其转换为矢量并用于查询数据库,返回前n个提示及其对应的图像。我们使用以下步骤搜索MyScale数据库:
第一步是将提示(问题)转换为矢量,如以下代码片段所示:
question = 'A cat is sleeping on the sofa' emb_query = retriever.encode(question).tolist()第二步是运行查询,搜索数据集并返回前no个提示(文本)及其对应的图像,如以下代码片段所示:
top_k = 2 results = client.query(f""" SELECT prompt, url, distance(prompt_vector, {emb_query}) as dist FROM Prompt_text_900k ORDER BY dist LIMIT {top_k} """) summaries = {'prompt': [], 'url': []} for res in results.named_results(): summaries['prompt'].append(res["prompt"]) summaries['url'].append(res["url"])
查询结果如以下代码片段所示:
{'prompt':['`two cute calico cats sleeping inside a cozy home in the evening, two multi - colored calico cats`','`two cats sleeping by the window Chinese new year digital art painting by makoto shinkai`'],
'url': ['`https://image.lexica.art/full_jpg/c6fc8242-86b6-4a2c-adee-3053bb345147`','https://image.lexica.art/full_jpg/06c4451c-ce40-4926-9ec7-0381f3dcc028']}
URL指向的图像如下:


# 生成新图像
使用GPT4的API,我们可以根据从此查询返回的数据创建新的提示,如以下代码片段所示:
system_message = f"""
Please provide a more native-sounding rewrite of the user-input
image generation prompt based on the following description
{summaries}
"""
使用这些新的提示将生成以下图像:


类似的流程也可以用于图像检索。
# 结论
个性化图像是AIGC趋势的核心。使用稳定扩散和LLM,可以创建视觉上引人注目的内容。通过MyScale,您可以使用其全面的矢量数据库找到合适的提示,如本文所述。用户可以通过MyScale与稳定扩散和LLM一起克服挑战,完善创造力,并与AIGC进行交互,从而产生独特的AI生成内容。
 京公网安备 11010802042981号
京公网安备 11010802042981号