
# Einführung in MyScale
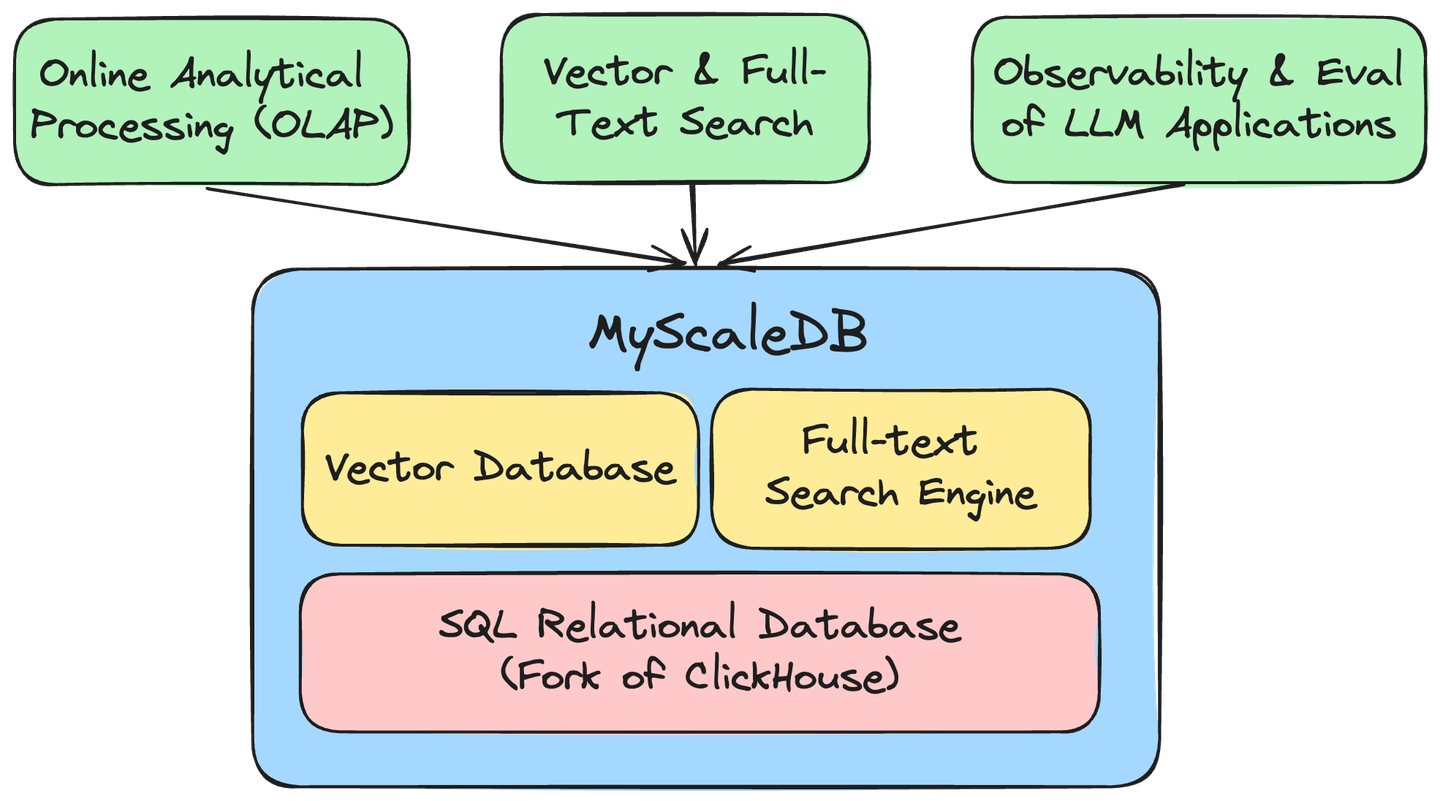
MyScale ist eine cloudbasierte Datenbank, optimiert für KI-Anwendungen und -Lösungen, aufgebaut auf der Open-Source-Datenbank ClickHouse, die es uns ermöglicht, massive Mengen an strukturierten und Vektordaten effektiv zu verwalten, um robuste KI-Anwendungen zu entwickeln. Einige der bedeutendsten Vorteile von MyScale sind:
- Für KI-Anwendungen entwickelt: Verwaltet und unterstützt die analytische Verarbeitung strukturierter und vektorisierter Daten auf einer einzigen Plattform.
- Für hohe Leistung entwickelt: Modernste OLAP-Datenbankarchitektur zur Durchführung von Operationen auf vektorisierten Daten mit unglaublicher Geschwindigkeit.
- Für universelle Zugänglichkeit entwickelt: SQL ist die einzige Programmiersprache, die zur Interaktion mit MyScale benötigt wird.
Im Vergleich zu den angepassten APIs anderer Produkte/Plattformen ist MyScale einfacher zu bedienen und somit für eine große Programmiergemeinschaft geeignet. MyScale eliminiert die Notwendigkeit mehrerer, teurer Data-Warehousing-Produkte, die unterschiedliche Abfragesprachen erfordern, durch kosteneffiziente Unterstützung für Datenmanagement, hervorragende lineare Skalierbarkeit und Standard-SQL-Unterstützung. In einer einzigen Schnittstelle kann eine SQL-Abfrage gleichzeitig und schnell verschiedene Datenmodalitäten nutzen, um komplexe KI-Anforderungen zu bewältigen, die sonst mehr Schritte und Zeit erfordern würden.
MyScales proprietäre MSTG-Vektor-Engine nutzt NVMe-SSDs, um die Datendichte um den Faktor 10 zu erhöhen. Diese Weiterentwicklung ermöglicht es MyScale, selbst die spezialisiertesten Vektordatenbanken (opens new window) um das 4- bis 10-fache in Bezug auf Leistung und Kosteneffizienz zu übertreffen. Die Einbindung eines Volltextsuchindex (FTS) integriert nahtlos Hochleistungstextsuchfunktionen und positioniert MyScale als ein effizientes Upgrade zu ElasticSearch (opens new window). Darüber hinaus bietet MyScale Telemetry (opens new window) umfassende Beobachtungsmöglichkeiten für LLM-Systeme, die nahtlose Überwachung und effizientes Debuggen gewährleisten.
Durch die Integration der Funktionen einer SQL-Datenbank/eines Data-Warehouses, einer Vektordatenbank und einer Volltextsuchmaschine in ein einziges, effizientes System reduziert MyScale die Infrastruktur- und Wartungskosten erheblich. Diese Vereinheitlichung erleichtert nicht nur gemeinsame Datenabfragen und Analysen, sondern schafft auch eine robuste und vielseitige Datenbasis, die für alle KI-Anwendungen unerlässlich ist.
# Schlüsselkonzepte
MyScale ist in der Lage, schnelle und präzise Abfragen über verschiedene Datenmodalitäten hinweg durchzuführen, basierend auf den folgenden Schlüsselkonzepten.
# Ähnlichkeitsmetriken
Es gibt zwei verschiedene Ansätze zur Messung der semantischen Ähnlichkeit zwischen zwei Datenobjekten:
- Unimodal (Bild-Bild oder Text-Text): Unimodale Ähnlichkeit misst die semantische Ähnlichkeit zwischen Objekten desselben Datentyps.
- Multimodal (Bild-Text): Multimodale Ähnlichkeit misst die semantische Ähnlichkeit zwischen Objekten unterschiedlicher Datentypen.
Die semantische Ähnlichkeit zwischen zwei Datenobjekten kann durch eine Punktzahl, die als Ähnlichkeitsmetrik bezeichnet wird, dargestellt werden. Die Wahl einer guten Ähnlichkeitsmetrik zur Darstellung der semantischen Ähnlichkeiten in einer großen Datenbank von Objekten ist entscheidend für die Leistung der Datenklassifizierung und -clustering in MyScale.
Die Wahl einer guten Ähnlichkeitsmetrik zur Darstellung der semantischen Ähnlichkeiten in einer großen Datenbank von Objekten ist für die Leistung der Datenklassifizierung und -clustering in MyScale unerlässlich. Drei der beliebteren Metriken sind:
- Euklidischer Abstand (L2): L2 wird häufig in Computer-Vision-Anwendungen (CV) verwendet.
- Inneres Produkt (IP): IP wird am häufigsten in Natural Language Processing (NLP)-Anwendungen verwendet.
- Kosinus-Ähnlichkeit: Im Gegensatz zu IP, das die "Größe" und "Winkel" berücksichtigt, die als Vektoren zwischen zwei Objekten dargestellt werden, vergleicht die Kosinus-Ähnlichkeit nur die Unterschiede in den "Winkeln" bei normalisierten Daten.
# Suchalgorithmen
Ein Einbettungsvektor (oder Vektor) ist eine numerische Darstellung eines Objekts, Konzepts oder einer Entität in einem mehrdimensionalen Raum. Er wird häufig verwendet, um Natural Language Processing (NLP)-Texte, IoT-Sensordaten, Fotos aus sozialen Medien, biologische und chemische Strukturen oder andere Datenobjekte so darzustellen, dass ihre semantischen Beziehungen und zusätzlichen Kontextinformationen erfasst werden.
Einbettungen sind darauf ausgelegt, bedeutungsvolle Merkmale oder Eigenschaften der Daten in einem niedrigdimensionalen Raum zu erfassen, was es maschinellen Lernalgorithmen erleichtert, die Daten zu verarbeiten und zu analysieren.
TIP
Moderne Einbettungstechniken werden verwendet, um unstrukturierte Daten in Vektoren umzuwandeln und hochdimensionale Daten in eine kompaktere und strukturiertere Form zu bringen.
Um die semantische Ähnlichkeit zwischen zwei Objekten zu vergleichen, geben Sie der MyScale-Datenbank einen Abfragevektor. MyScale verwendet dann Suchalgorithmen wie Approximate Nearest Neighbor (ANN), um schnell und präzise eine Liste ähnlicher Vektoren zum Abfragevektor zurückzugeben.
# Verwendung von SQL mit MyScale
Im Gegensatz zu proprietären Vektordatenbanken wie Pinecone, Milvus, Qdrant und Weaviate basiert MyScale auf der Open-Source-SQL-kompatiblen Datenbank ClickHouse. Dafür gibt es mehrere Gründe, darunter:
- Wir können unseren Benutzern eine funktionsreiche Datenbank zur Verfügung stellen, indem wir von ClickHouses ausgereiftem Codebase und Ökosystem profitieren.
- SQL wird weit verbreitet zur Verwaltung relationaler Datenbanken verwendet. Mit der SQL-Unterstützung von MyScale können Entwickler und Datenanalysten ihr vorhandenes Wissen und ihre Fähigkeiten nutzen, was die Integration und Verwendung erleichtert.
- SQL unterstützt eine Vielzahl von Funktionen zur Datenmanipulation, Abfrage und Berichterstellung. Daher können Benutzer mit MyScale komplexe Abfragen durchführen und Daten auf viele verschiedene Arten analysieren, da es vollständig mit SQL kompatibel ist.
- Da MyScale auf ClickHouse aufbaut, bietet es nicht nur schnelle und skalierbare Leistung für die Vektorsuche, sondern auch für die gefilterte Vektorsuche und komplexe SQL plus Vektorabfragen, wie das Verbinden von Vektorsuchergebnissen mit einer anderen Tabelle.
# Warum ist das wichtig?
Mit dem exponentiellen Wachstum komplexer Daten werden zukunftssichere Lösungen benötigt, die mit neuen Datenmodalitäten, Datenbankgrößen und Herausforderungen bei der Beantwortung von Abfragen umgehen können. Dies ist wichtig, darf jedoch nicht auf Kosten der Rechenleistung und der Integration zwischen verschiedenen Datenmodalitäten geschehen.
Neben traditionellen Datenformaten kann MyScale auch zukünftige Datenmodalitäten verarbeiten. In MyScale ist die Kombination von traditionellen strukturierten Daten mit Vektorsuchergebnissen in SQL ein leistungsstarker Ansatz, um komplexe KI-bezogene Fragen zu bewältigen und gleichzeitig die Leistung zu erhalten.
Lesen Sie weiter, um herauszufinden, wie MyScale funktioniert und wie Sie es in Ihre Lösung integrieren können.