
# Detección de objetos en Safari
El tutorial anterior demostró algunos usos básicos de la base de datos MyScale, como la inserción y consulta de vectores no estructurados Top-K. Y esta demostración intentará cubrir características más avanzadas en MyScale.
MyScale está diseñado para ofrecer una búsqueda de vectores de alto rendimiento con SQL a gran escala. Introducimos el conjunto de datos COCO (opens new window) como nuestra fuente de datos para hacer este tutorial más práctico, que contiene más de 280 mil imágenes y aproximadamente 1.3 millones de objetos anotados. La extracción y consulta de información a nivel de objeto requiere una comprensión más detallada de las imágenes. Además, es más grande y más difícil porque el número de objetos es mucho mayor que el número de imágenes, especialmente para un conjunto de datos como COCO.
Buscar objetos es una tarea complicada, y buscar entre miles de millones de objetos es aún más desafiante. Pero tiene más aplicaciones que la búsqueda a nivel de imagen. Por ejemplo, la comprensión a nivel de objeto puede reducir el trabajo en el etiquetado de datos y el proceso de anotación de objetos para muchas industrias.
La información a nivel de objeto tiene muchas formas en los datos. El cuadro delimitador es la solución más popular y económica para almacenarla. Utiliza un rectángulo que puede recortar el objeto de la imagen y una etiqueta que describe a qué categoría pertenece. Necesitamos guardar el rectángulo y su etiqueta o incrustación de etiqueta para consultas posteriores. Además de esto, también debemos tener en cuenta las relaciones entre los cuadros delimitadores. Las relaciones involucradas entre los cuadros delimitadores se pueden enumerar a continuación:
- Una imagen puede contener múltiples cuadros delimitadores de diferentes instancias.
- Los cuadros delimitadores pueden tener duplicados.
Teniendo en cuenta todos los factores anteriores, podemos dividirlos en dos partes: lo que MyScale puede hacer y lo que no puede hacer. La base de datos puede encargarse del primer factor utilizando una tabla de cuadros y una tabla de imágenes al mismo tiempo. También puede hacer más cosas como ordenar y agrupar objetos, búsqueda de múltiples criterios y cálculo de la probabilidad de predicción. Solo necesitas ocuparte del segundo: eliminar los cuadros duplicados, lo cual se puede implementar fácilmente con la supresión de no máximos (NMS).
# Descripción general del conjunto de datos
Seleccionamos 287,104 imágenes del conjunto de datos COCO, incluyendo todas las imágenes del conjunto de entrenamiento/prueba/validación/sin etiquetar. Contiene alrededor de 1.3 millones de imágenes anotadas en 81 clases. Elegimos este conjunto de datos por su alta variabilidad y densidad de objetos, lo que puede sorprendernos al recuperar categorías de objetos no cubiertas. Por ejemplo, detectar personas con camisas blancas, armarios e incluso señales de stop:
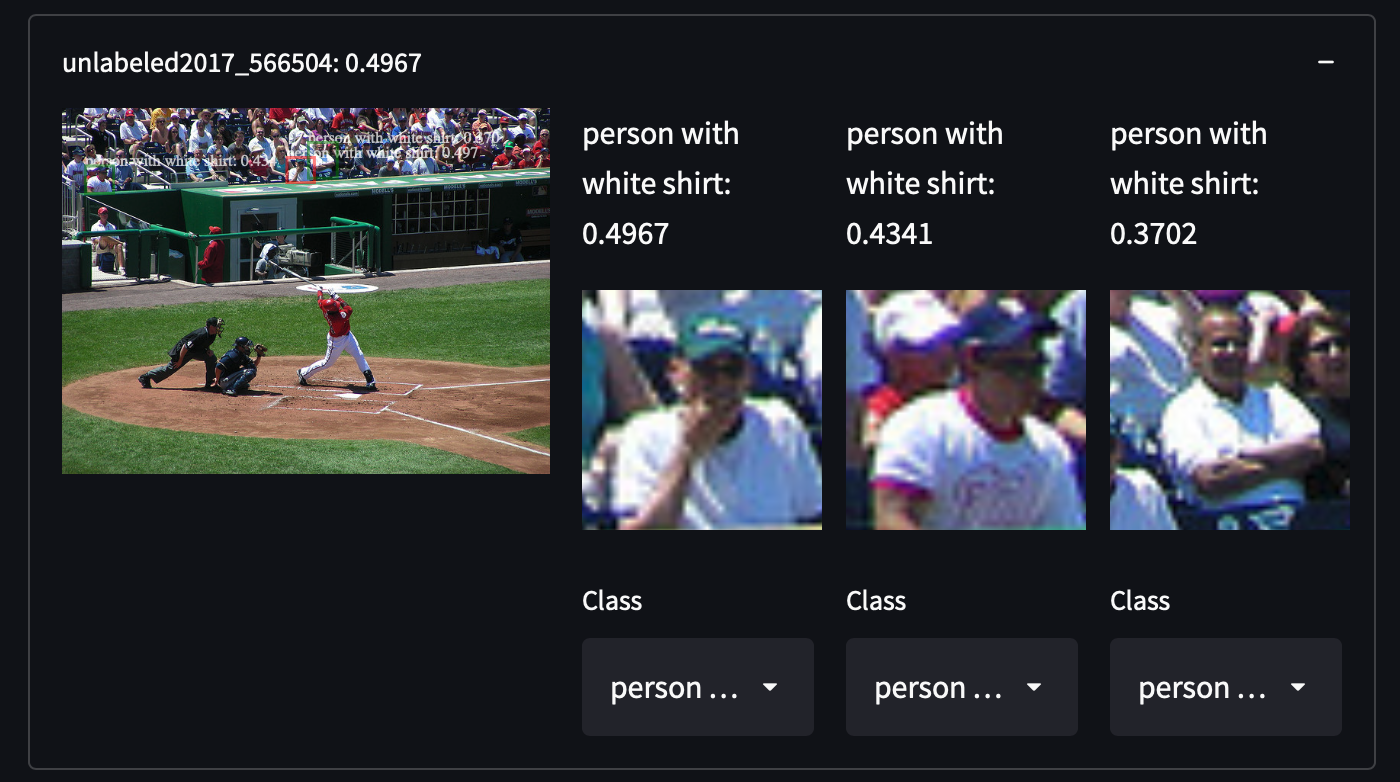
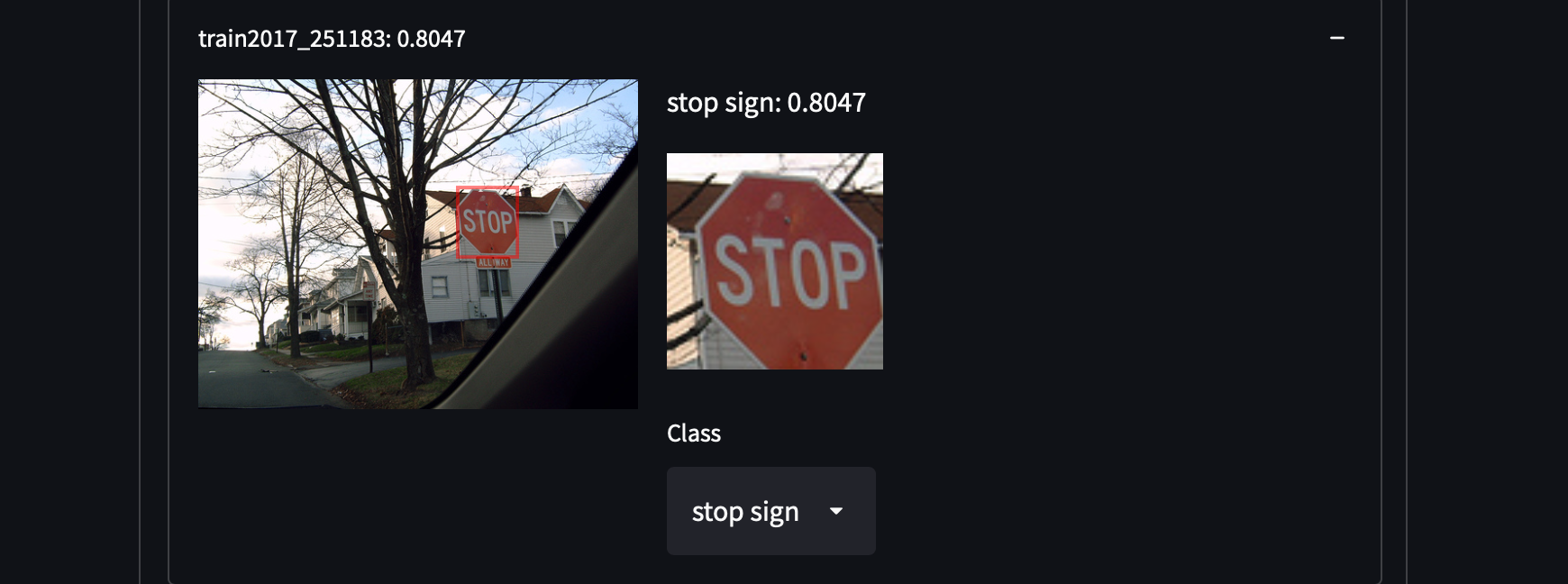
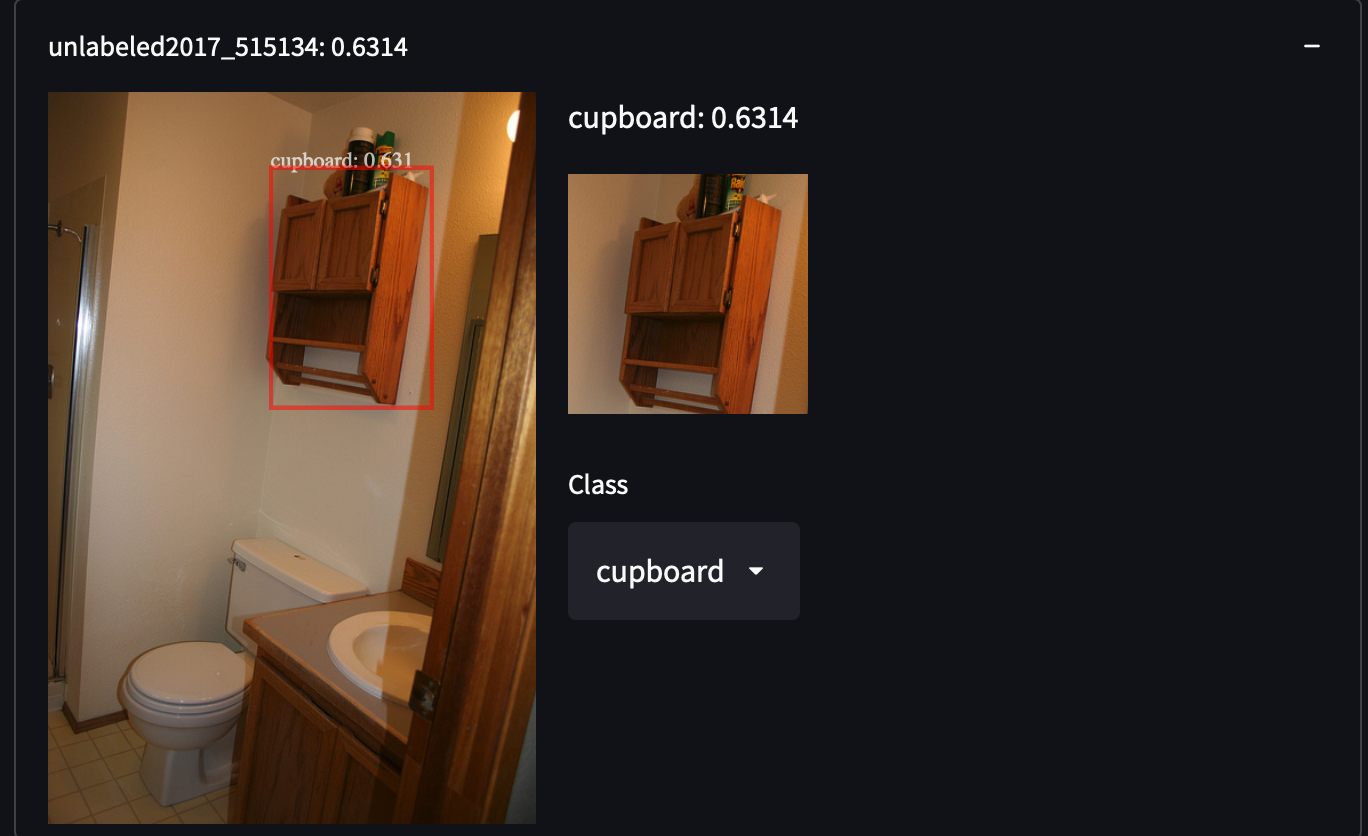 Es bastante fácil obtener el conjunto de datos COCO. Solo descarga todos esos archivos JSON y analízalos.
Es bastante fácil obtener el conjunto de datos COCO. Solo descarga todos esos archivos JSON y analízalos.
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
unzip annotations_trainval2017.zip
Después de cargar y analizar los datos, encontrarás una URL de imagen única bajo la clave coco_url para cada imagen individual. Utilizaremos una imagen específica para demostrar cómo se extrae una característica.
import requests
from PIL import Image
from io import BytesIO
from transformers import OwlViTProcessor, OwlViTForObjectDetection
response = requests.get("http://images.cocodataset.org/train2017/000000391895.jpg")
img = Image.open(BytesIO(response.content))
img_s = img.size
if img.mode in ['L', 'CMYK', 'RGBA']:
# L es escala de grises, CMYK utiliza canales de color alternativos
img = img.convert('RGB')
# Detección de objetos de vocabulario abierto
Los modelos de visión-texto están hechos para la magia negra. Pueden darte un clasificador con un solo hechizo. CLIP (opens new window) logra esto a nivel de imagen, permitiendo la clasificación de imágenes sin entrenamiento. Alinea características del dominio visual y textual con una pérdida contrastiva. Ya hemos visto su increíble rendimiento en la demostración de aprendizaje con pocos ejemplos (opens new window). Inspirado por CLIP, podría ser más interesante si aplicamos CLIP en pequeños parches y predecimos cuadros en esos pequeños parches. La característica alineada visión-texto para cada cuadro nos convertirá en un detector de cero disparos espontáneamente. ¡Y bingo! Así es como funciona OWLViT (opens new window).
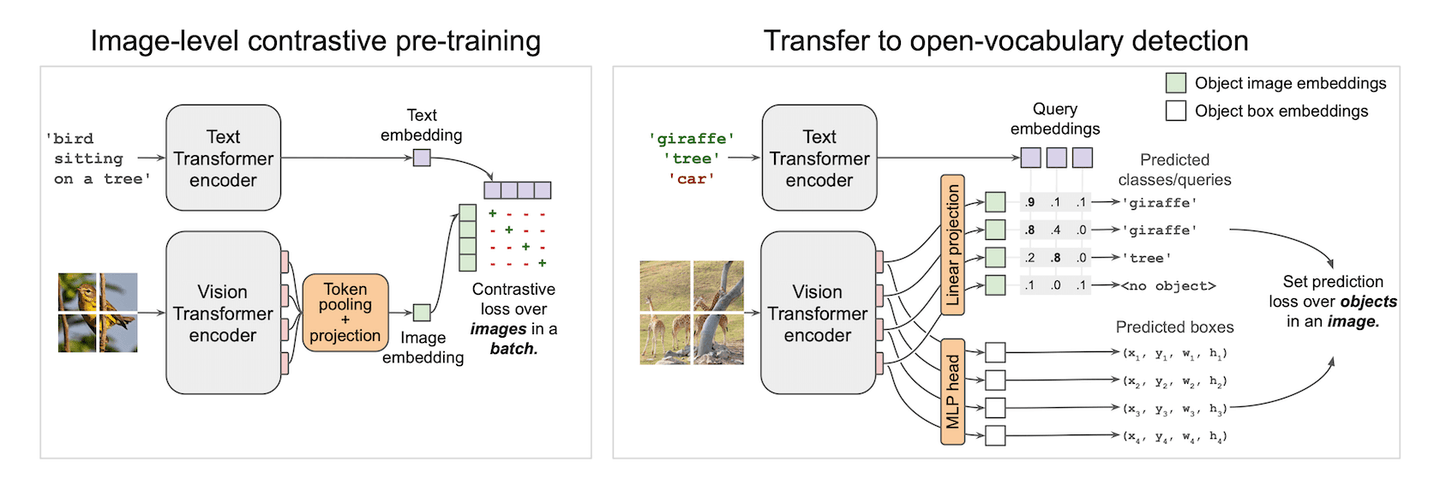
OWLViT divide la detección y clasificación de manera paralela. Dejará de lado la clase y te dará cuadros incluso si no tiene idea de lo que acaba de detectar. Y depende de ti darle significado a esos cuadros, utilizando una incrustación de consulta. Esto hace que nuestra búsqueda sea fácil y no requiere cálculos adicionales en la clasificación de RoI. Lo único que tenemos son cuadros y sus incrustaciones. Clasificar esos cuadros utilizando el producto interno entre el vector de consulta y la incrustación de clase nos dará objetos similares en los conjuntos de datos.
Sin embargo, hay una trampa en la que podrías caer cuando logres diseñar una solución de almacenamiento. La salida real de la red es un poco más complicada que la figura demostrada. Además de las dos salidas dibujadas en la figura, también genera una escala y un escalar de desplazamiento para ampliar o reducir la confianza en la predicción. Por lo tanto, la fórmula de predicción real debería escribirse y simplificarse de la siguiente manera:
Volviendo al código. Como de costumbre, preprocesamos la imagen para que se ajuste a la entrada del modelo.
from transformers import OwlViTProcessor, OwlViTForObjectDetection
name = "google/owlvit-base-patch32"
model = OwlViTForObjectDetection.from_pretrained(name)
processor = OwlViTProcessor.from_pretrained(name)
# Preprocesar imagen
ret = processor(text=txt, images=img, return_tensor='pt')
img = ret['pixel_values'][0]
Hicimos algunos ajustes dentro de OWLViT porque queremos extraer manualmente la característica de la imagen y los cuadros utilizando la fórmula anterior.
def extract_visual_feature(img):
with torch.no_grad():
model.eval()
# Extraer característica de ViT
vision_outputs = model.owlvit.vision_model(
pixel_values=img,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
use_hidden_state=False,
)
last_hidden_state = vision_outputs[0]
image_embeds = model.owlvit.vision_model.post_layernorm(
last_hidden_state)
# Cambiar tamaño del token de clase
new_size = tuple(np.array(image_embeds.shape) - np.array((0, 1, 0)))
class_token_out = torch.broadcast_to(image_embeds[:, :1, :], new_size)
# Combinar incrustación de imagen con tokens de clase
image_embeds = image_embeds[:, 1:, :] * class_token_out
image_embeds = model.layer_norm(image_embeds)
# Cambiar tamaño a [batch_size, num_patches, num_patches, hidden_size]
new_size = (
image_embeds.shape[0],
int(np.sqrt(image_embeds.shape[1])),
int(np.sqrt(image_embeds.shape[1])),
image_embeds.shape[-1],
)
image_embeds = image_embeds.reshape(new_size)
# Últimos estados ocultos de los transformadores de texto y visión
vision_model_last_hidden_state = vision_outputs[0]
feature_map = image_embeds
batch_size, num_patches, num_patches, hidden_dim = feature_map.shape
image_feats = torch.reshape(
feature_map, (batch_size, num_patches * num_patches, hidden_dim))
# Predecir cuadros de objetos
pred_boxes = model.box_predictor(image_feats, feature_map)
image_class_embeds = model.class_head.dense0(image_feats)
image_class_embeds /= torch.linalg.norm(
image_class_embeds, dim=-1, keepdim=True) + 1e-6
# Aplicar un desplazamiento y escala aprendibles a los logit
logit_shift = model.class_head.logit_shift(image_feats)
logit_scale = model.class_head.logit_scale(image_feats)
logit_scale = model.class_head.elu(logit_scale) + 1
prelogit = torch.cat([image_class_embeds * logit_scale,
logit_shift * logit_scale], dim=-1)
return prelogit, image_class_embeds, pred_boxes
# ¡EXTRAER!
prelogit, image_class_embeds, pred_boxes = extract_visual_feature(
img.unsqueeze(0))
¡Y el resto depende de ti! Todo lo que necesitas hacer es almacenar esos datos y subirlos a MyScale. ¡Puedes seguir nuestra referencia de SQL para insertar tus propios datos!
# Mejores prácticas para el diseño de almacenamiento y consultas
Tenemos dos tipos de instancias: cuadros e imágenes. Los cuadros pertenecen a las imágenes. Por lo tanto, es más eficiente y flexible almacenar los datos en dos tablas.
# Diseño de almacenamiento
# Tabla de imágenes
| COLUMNA | TIPO DE DATO | |
|---|---|---|
| img_id | String | PRIMARY |
| img_url | String | |
| img_w | Int32 | |
| img_h | Int32 |
# Tabla de objetos
| COLUMNA | TIPO DE DATO | |
|---|---|---|
| obj_id | String | PRIMARY |
| img_id | String | (FOREIGN) |
| box_cx | Float32 | |
| box_cy | Float32 | |
| box_w | Float32 | |
| box_h | Float32 | |
| class_embedding | Array(Float32) | longitud = 512 |
| prelogit | Array(Float32) | longitud = 513 |
SQL de construcción de tablas:
CREATE TABLE IMG_TABLE (
`img_id` String,
`img_url` String,
`img_w` Int32,
`img_h` Int32
) ENGINE = MergeTree PRIMARY KEY img_id
ORDER BY
img_id SETTINGS index_granularity = 8192
CREATE TABLE OBJ_TABLE (
`obj_id` String,
`img_id` String,
`box_cx` Float32,
`box_cy` Float32,
`box_w` Float32,
`box_h` Float32,
`logit_resid` Float32,
`class_embedding` Array(Float32),
`prelogit` Array(Float32),
CONSTRAINT cls_emb_len CHECK length(class_embedding) = 512,
CONSTRAINT prelogit_len CHECK length(prelogit) = 513,
VECTOR INDEX vindex prelogit TYPE MSTG('metric_type=IP')
) ENGINE = MergeTree PRIMARY KEY obj_id
ORDER BY
obj_id SETTINGS index_granularity = 8192
Utilizamos MSTG como nuestro algoritmo de búsqueda de vectores. Para obtener detalles de configuración, consulte Búsqueda de vectores.
# Diseño de consulta
Tratamos cada frase del usuario como una consulta individual. Y recuperamos los mejores K para cada una de ellas. Esas consultas deben agruparse por imágenes y también ordenarse según una puntuación combinada. Por ejemplo, una imagen que contiene varios objetos relevantes debe tener una clasificación más alta que una imagen que contiene solo uno relevante. Por lo tanto, también necesitamos usar SQL para calcular eso.
# Subconsultas: Evitar demasiadas lecturas en la columna de datos grandes
Para cada consulta de texto que recibimos, consultamos class_embedding, las cajas predichas y su confianza, y la información de su imagen. La columna class_embedding no es realmente necesaria en aplicaciones normales. Pero para un aprendiz de pocos disparos como este, necesitamos esos vectores originales para entrenar nuestros clasificadores. Esto nos plantea un desafío en manejar columnas de datos grandes y buscarlos con múltiples vectores y también reducir el tráfico de red innecesario para aumentar la velocidad. Es una buena muestra de diseño y optimización avanzados de consultas.
De manera intuitiva, con nuestra función de distancia de vector, podemos componer nuestro SQL de la siguiente manera para lograr nuestro objetivo:
-- Por ejemplo, tenemos una consulta de etiqueta `0` y _xq0 como nuestro vector de consulta
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l,
distance('nprobe=32')(prelogit, {_xq0}) AS dist
FROM OBJ_TABLE
JOIN IMG_TABLE
ON OBJ_TABLE.img_id = IMG_TABLE.img_id
ORDER BY dist DESC LIMIT 10
Esto es correcto, pero no eficiente. Esta consulta leerá todas las columnas, incluidos los enormes datos de vector almacenados en la columna class_embedding. Esto será un desastre y arrastrará la velocidad de búsqueda al suelo. Tendrá que esperar a que la base de datos lea los datos para obtener su resultado. Por lo tanto, tenemos que cambiar la forma en que hacemos la consulta.
El verdadero objetivo de nuestra consulta es recuperar los vecinos más cercanos del vector de consulta y su información. Podemos dividirlo en dos pasos, en otras palabras, dos subconsultas. Primero, obtener los obj_id de esas cajas y luego las posiciones de las cajas y las incrustaciones. WHERE también es útil para filtrar datos innecesarios. La consulta mejorada se ve así:
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
WHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
)
Usamos WHERE para filtrar los objetos que no están en el TopK antes de unir la tabla de imágenes y la tabla de objetos. Esto evita toneladas de lecturas en la columna class_embedding. Después de recortar esos datos no utilizados, podemos realizar una lectura ligera de lo que necesitamos para la consulta. ¡Genial, tenemos una consulta rápida y funcional en nuestras manos!
# Agrupación de subconsultas
Lo primero es lo primero. Necesitamos fusionar todas las subconsultas antes de agruparlas. UNION ALL (opens new window) es útil cuando tienes varias subconsultas para recopilar. Además, sabemos que algunas imágenes pueden contener varios objetos. No queremos que las cajas estén dispersas por todos los resultados, así que necesitamos agruparlas. Ahora es el momento de usar la cláusula GROUP BY. Pero debes colocar cada columna consultada debajo de una función de agregación o después del GROUP BY. En este escenario, usamos groupArray (opens new window), que concatena todos los resultados agrupados en un array. Por lo tanto, la versión final de nuestra consulta será:
SELECT img_id, groupArray(obj_id) AS box_id, img_url, img_w, img_h,
groupArray(box_cx) AS cx, groupArray(box_cy) AS cy,
groupArray(box_w) AS w, groupArray(box_h) AS h,
groupArray(l) as label, groupArray(class_embedding) AS cls_emb
FROM (
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
PREWHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq0}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
)
UNION ALL
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 1 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
PREWHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq1}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
))
GROUP BY img_id, img_url, img_w, img_h
# Reducción del tráfico de red entre su aplicación y MyScale
Las aplicaciones pueden quedar varadas con una conexión de red débil, y supongamos que no puedes hacer nada al respecto. Si eso sucede, no te desesperes. MyScale es más poderoso de lo que imaginas. Reducir el tráfico de red será tu único objetivo, pero ¿cómo? Si no recuperas datos de incrustación, no puedes calcular el gradiente en tu servidor... En realidad, este cálculo no necesariamente se debe realizar en tu servidor, puede ocurrir dentro de la base de datos. Como puede calcular la salida de la red con la salida de la capa intermedia y ordenarla, también puedes esperar que calcule el gradiente. Calcular el gradiente puede ayudarte a evitar recuperar directamente las incrustaciones de la base de datos, lo que generalmente requiere más de 20 MB de datos para una sola consulta. Eso podría llevar hasta 20 segundos con un ancho de banda de 10 Mbps. Es completamente inaceptable en algunos escenarios.
Veamos cómo se puede hacer. Supongamos que adoptamos la entropía cruzada binaria como función de pérdida para entrenar el clasificador de pocos disparos, podemos obtener trivialmente
donde
SELECT sumForEachArray(arrayMap((x,p,y)->arrayMap(i->i*(p-y), x), X, P, Y)) AS grad FROM (
SELECT groupArray(arrayPopBack(prelogit)) AS X,
groupArray(1/(1+exp(-arraySum(arrayMap((x,y)->x*y, prelogit, <your-weight>))))) AS P,
<your-label> AS Y
FROM <your-db>
WHERE obj_id IN [<your-objects>]
)
El SQL anterior puede darte el gradiente de inmediato. Tu aplicación solo necesita encargarse del resto: aplicar este gradiente con una tasa de aprendizaje. Créeme, este truco es SUPER rápido.
# Usos avanzados con funciones de array
Durante la consulta, necesitamos calcular datos que no existen en ninguna columna. A diferencia de las agregaciones (opens new window), necesitamos calcular en objetos de array elemento por elemento. Así que aquí entran en juego las funciones de array (opens new window). ClickHouse proporciona muchas funciones útiles que nos ayudan a manipular arrays. Los algoritmos de búsqueda de vectores de MyScale son compatibles con el tipo Array (opens new window) de ClickHouse. Por lo tanto, puedes utilizar todas las funciones de array en ClickHouse. Aquí tenemos dos ejemplos para demostrar cómo usar las funciones de array.
# Cálculo de la confianza de predicción
Recordando la fórmula anterior, la confianza en la predicción se calcula como un producto interno mapeado por una función sigmoide. Aquí usamos arrayMap (opens new window) y arraySum (opens new window) para calcular el logit final. La función de cálculo se ve así:
SELECT 1/(1+exp(-arraySum(arrayMap((x,y)->x*y, prelogit, {_xq0})))) AS pred_logit
FROM OBJ_TABLE LIMIT 10
La función arrayMap multiplica elementalmente dos arrays: _xq0 y cada array de la columna prelogit. Esta función puede consumir tanto arrays individuales como arrays de una columna.
# Cálculo de la puntuación de la imagen
Para brindar una mejor experiencia al usuario, deberíamos clasificar las imágenes según su relevancia general. Aquí proporcionamos un ejemplo simple para describir la relevancia general de la imagen con las funciones de array de ClickHouse. En esta sección, presentaremos arrayReduce (opens new window). Esta función es un grupo de funciones y una de ellas es maxIf. Puede calcular el valor máximo en un array en función de una máscara dada.
Definimos nuestra relevancia general de la imagen como una suma de la máxima logit de clase. Para ser más concretos, primero calculamos la máxima confianza por una etiqueta de clase y luego las sumamos. Esto significa que cuanto más clases tengas en la imagen, mayor relevancia tendrás para la imagen. Además, cuanto mayor sea la confianza máxima, mayor será la relevancia.
Obtenemos el pred_logit calculado anteriormente y la expresión se ve así:
arraySum(arrayFilter(x->NOT isNaN(x),
array(arrayReduce('maxIf', groupArray(pred_logit), arrayMap(x->x=0, label)),
arrayReduce('maxIf', groupArray(pred_logit), arrayMap(x->x=1, label)))))
Primero, calculamos una máscara para una etiqueta dada con la función arrayMap, y luego la usamos para calcular la puntuación máxima de cada etiqueta en la consulta del usuario.
Convertimos el conjunto de puntuaciones máximas calculadas en un array y calculamos su suma si alguno de sus valores no es Nan. Esto te dará la puntuación general de la imagen de inmediato.
# En resumen
Este tutorial te brinda un ejemplo de uso avanzado en MyScale. Cubre subconsultas, agrupación, funciones de array y diseño eficiente de SQL en MyScale. Aquí hay algunas conclusiones que pueden ser útiles:
- Para una distancia de vector compleja: Intenta hacer las cosas lindas para MyScale. La mayoría de las funciones de distancia siempre se pueden convertir en una de las siguientes: distancia L2, distancia coseno o producto interno. Asegúrate de saber qué función vas a utilizar.
- Para SQL de vector complejo: Deja las columnas de vectores grandes atrás y procesa/recupera primero las columnas pequeñas.
- Para cálculos avanzados: Las funciones de array siempre serán tus mejores amigos. Calcular esos números con SQL te brinda poder adicional: ordenar/seleccionar será barato si lo haces dentro de MyScale y también te ahorrará centavos al día en menos cálculos en un servidor web.