
# Objekterkennung Safari
Das vorherige Tutorial hat einige grundlegende Anwendungen der MyScale-Datenbank gezeigt, wie das Einfügen und Abfragen von Top-K unstrukturierten Vektoren. In diesem Demo werden wir versuchen, fortgeschrittenere Funktionen in MyScale abzudecken.
MyScale ist darauf ausgelegt, eine leistungsstarke Vektorsuche mit SQL in Milliarden von Maßstäben zu ermöglichen. Wir verwenden den COCO-Datensatz (opens new window) als Datenquelle, um dieses Tutorial praktischer zu gestalten. Der Datensatz enthält mehr als 280.000 Bilder und etwa 1,3 Millionen annotierte Objekte. Die Extraktion und Abfrage von objektspezifischen Informationen erfordert ein feineres Verständnis von Bildern. Außerdem ist es größer und schwieriger, da die Anzahl der Objekte viel größer ist als die Anzahl der Bilder, insbesondere für einen Datensatz wie COCO.
Die Suche nach Objekten ist eine komplexe Aufgabe, und die Suche unter Milliarden von Objekten ist noch herausfordernder. Aber sie hat mehr Anwendungen als die Suche auf Bilderebene. Zum Beispiel kann das Verständnis auf Objektebene den Aufwand bei der Datenbeschriftung und der Objektannotation in vielen Branchen reduzieren.
Objektspezifische Informationen können verschiedene Formen in den Daten annehmen. Die Bounding Box ist die beliebteste und kostengünstigste Lösung zur Speicherung. Sie verwendet ein Rechteck, das das Objekt aus dem Bild ausschneiden kann, und ein Label, das angibt, zu welcher Kategorie es gehört. Wir müssen das Rechteck und sein Label oder das Label-Embedding für weitere Abfragen speichern. Darüber hinaus müssen wir uns auch um die Beziehungen zwischen den Bounding Boxes kümmern. Die Beziehungen zwischen den Bounding Boxes können wie folgt aufgelistet werden:
- Ein Bild kann mehrere Bounding Boxes verschiedener Instanzen enthalten.
- Bounding Boxes können Duplikate haben.
Unter Berücksichtigung aller oben genannten Faktoren können wir sie in zwei Teile aufteilen: den Teil, den MyScale erledigen kann, und den Teil, den es nicht kann. Die Datenbank kann sich um den ersten Faktor kümmern, indem sie gleichzeitig eine Box-Tabelle und eine Bild-Tabelle verwendet. Sie kann auch weitere Dinge wie Objektsortierung und -gruppierung, Mehrkriterien-Suche und Berechnung der Vorhersagewahrscheinlichkeit durchführen. Sie müssen sich nur um den zweiten Teil kümmern: das Eliminieren von duplizierten Boxen, was einfach mit der Non-Maximum Suppression (NMS) implementiert werden kann.
# Übersicht über den Datensatz
Wir haben 287.104 Bilder aus dem COCO-Datensatz ausgewählt, einschließlich aller Bilder aus dem Trainings-/Test-/Validierungs-/Unbeschrifteten-Set. Der Datensatz enthält etwa 1,3 Millionen annotierte Bilder in 81 Klassen. Wir haben diesen Datensatz aufgrund seiner hohen Varianz und Dichte von Objekten ausgewählt, was uns Überraschungen bei der Suche nach unbekannten Objektkategorien geben kann. Zum Beispiel das Erkennen von Personen mit weißen Hemden, Schränken oder sogar Stoppschildern:
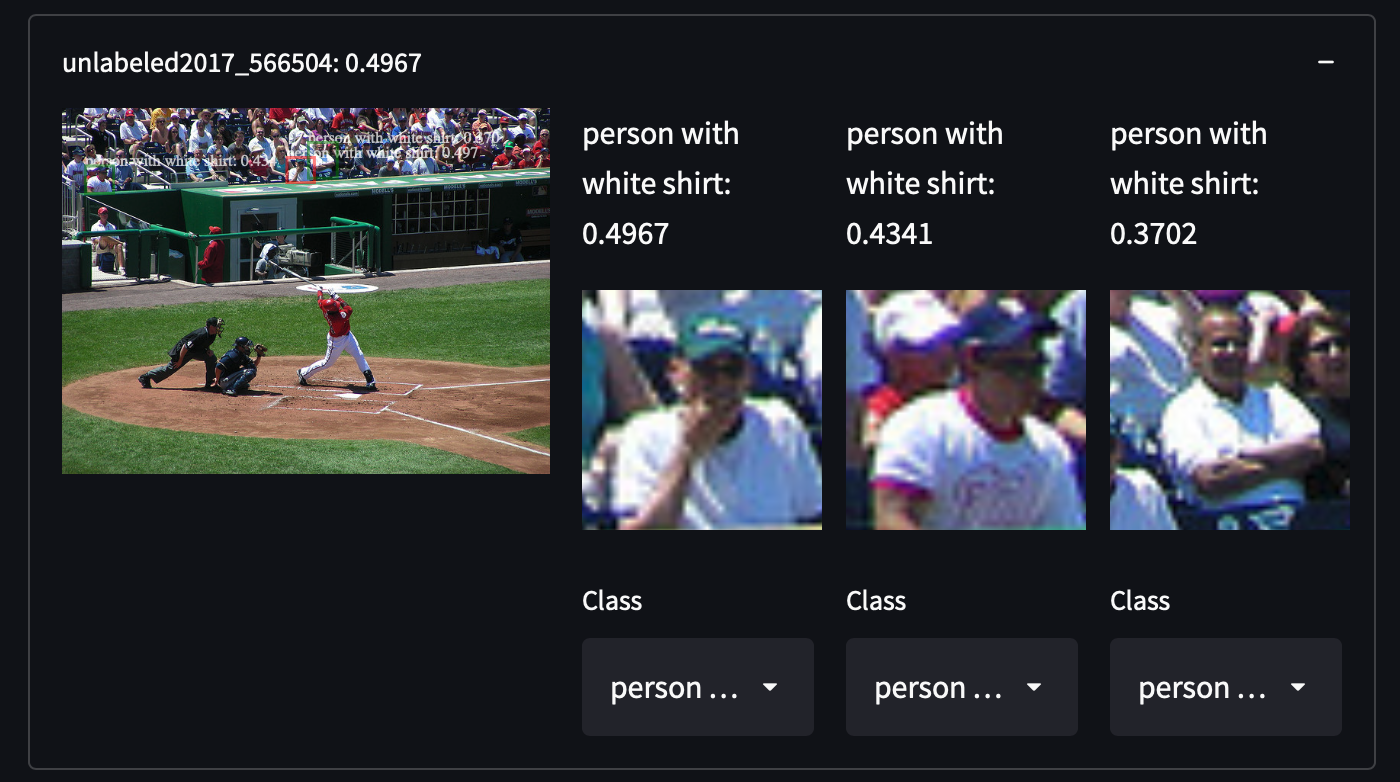
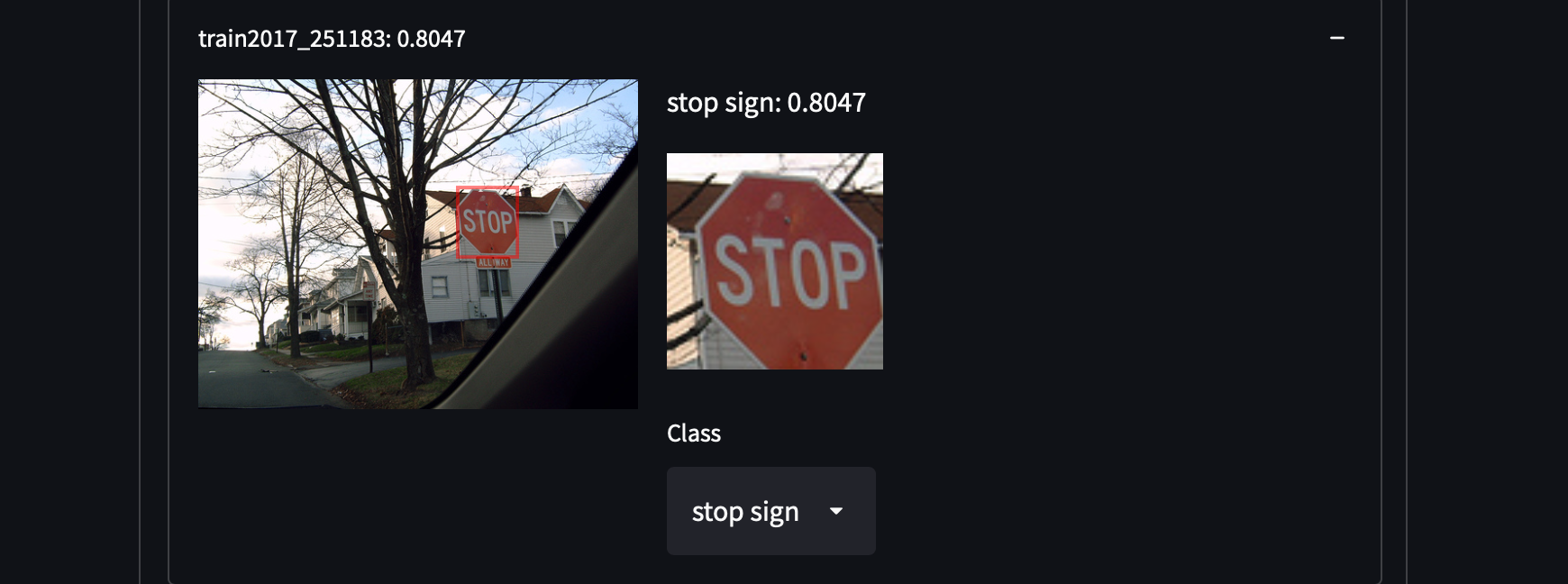
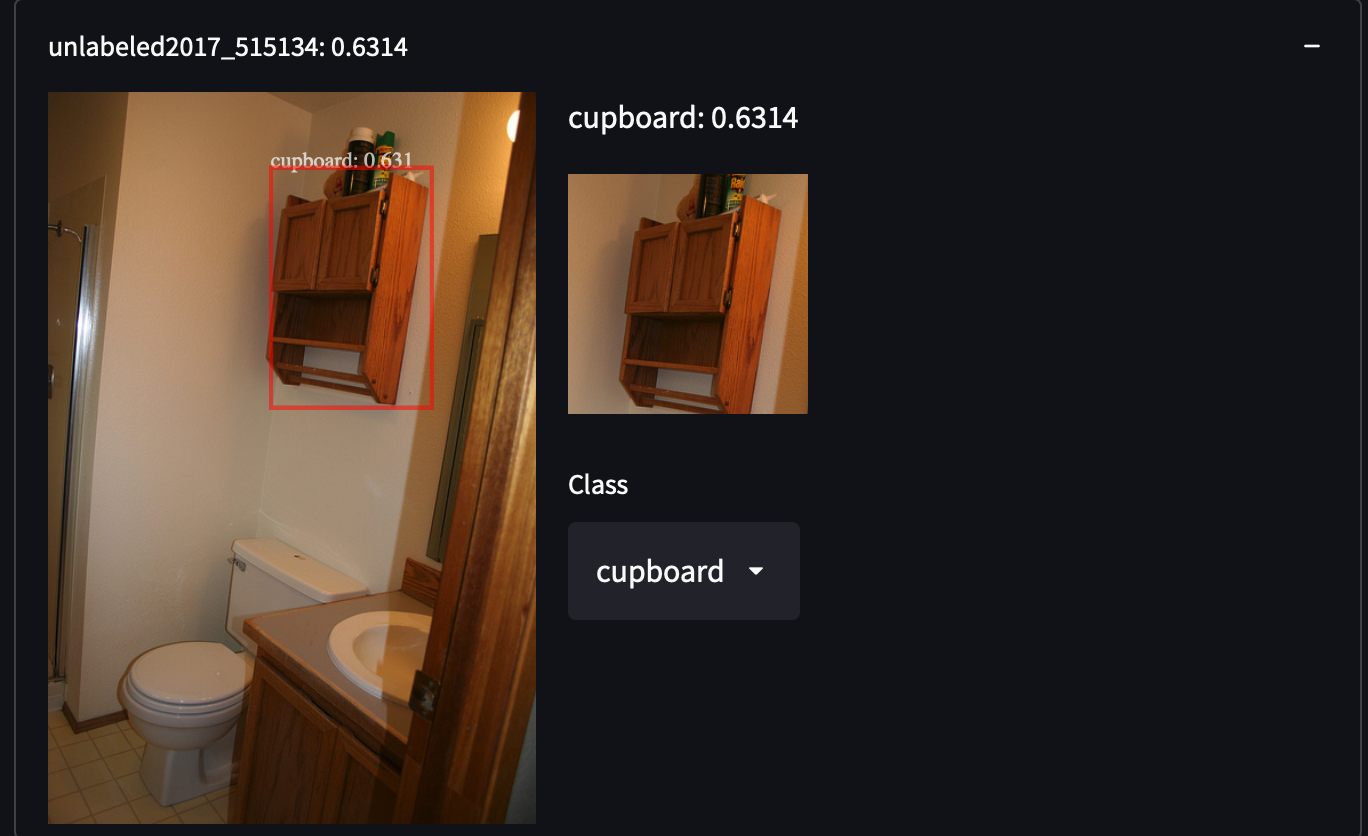 Es ist ziemlich einfach, den COCO-Datensatz zu erhalten. Laden Sie einfach alle JSON-Dateien herunter und analysieren Sie sie.
Es ist ziemlich einfach, den COCO-Datensatz zu erhalten. Laden Sie einfach alle JSON-Dateien herunter und analysieren Sie sie.
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
unzip annotations_trainval2017.zip
Nach dem Laden und Analysieren der Daten finden Sie für jedes einzelne Bild eine eindeutige Bild-URL unter dem Schlüssel coco_url. Wir werden ein bestimmtes Bild verwenden, um zu demonstrieren, wie ein Merkmal extrahiert wird.
import requests
from PIL import Image
from io import BytesIO
from transformers import OwlViTProcessor, OwlViTForObjectDetection
response = requests.get("http://images.cocodataset.org/train2017/000000391895.jpg")
img = Image.open(BytesIO(response.content))
img_s = img.size
if img.mode in ['L', 'CMYK', 'RGBA']:
# L ist Graustufen, CMYK verwendet alternative Farbkanäle
img = img.convert('RGB')
# Objekterkennung mit offener Vokabel
Vision-Text-Modelle sind für schwarze Magie gemacht. Sie können Ihnen einen Klassifizierer mit einem einzigen Zauber geben. CLIP (opens new window) erreicht dies auf der Bildebene und ermöglicht eine Null-Shot-Bildklassifizierung. Es gleicht Merkmale aus dem visuellen und textuellen Bereich mit einem kontrastiven Verlust ab. Wir haben bereits seine erstaunliche Leistung in der Demo zum Few-Shot-Learning (opens new window) gesehen. Inspiriert von CLIP könnte es noch interessanter sein, CLIP auf kleine Patches anzuwenden und auf diesen kleinen Patches Boxen vorherzusagen. Das ausgerichtete Vision-Text-Merkmal für jede Box macht uns spontan zu einem Zero-Shot-Detektor. Und bingo! So funktioniert OWLViT (opens new window).
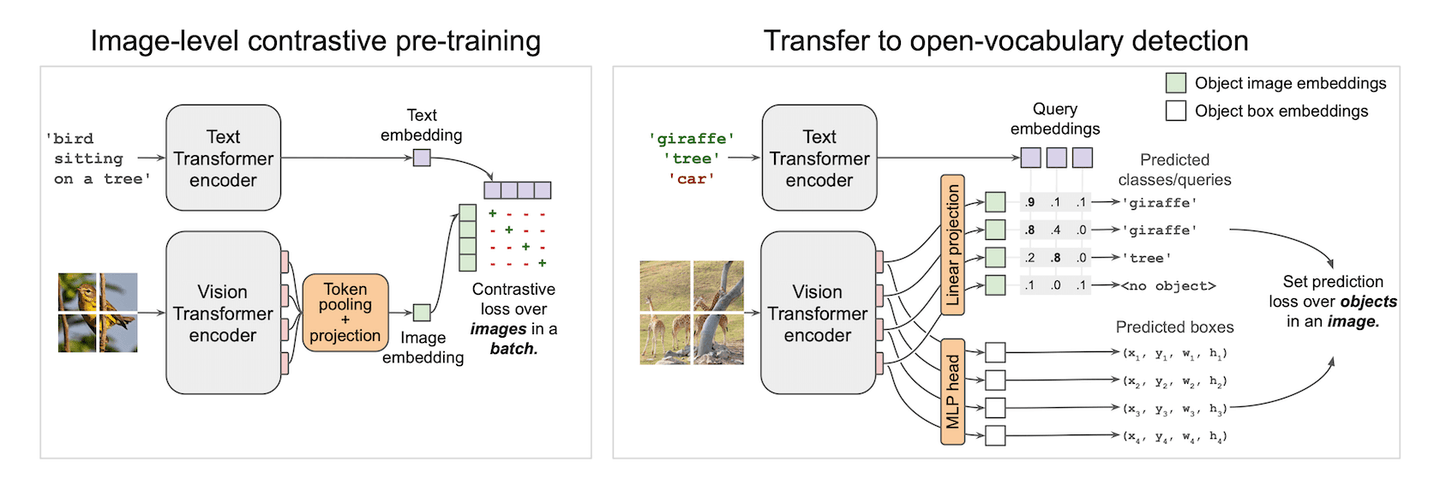
OWLViT teilt die Detektion und Klassifikation parallel auf. Es lässt die Klasse beiseite und gibt Ihnen Boxen, selbst wenn es keine Ahnung hat, was es gerade erkannt hat. Und es liegt an Ihnen, diesen Boxen Bedeutung zu geben, indem Sie ein Query-Embedding verwenden. Dies macht unsere Suche einfach und erfordert keine zusätzliche Berechnung bei der RoI-Klassifikation. Was wir haben, sind nur Boxen und ihre Embeddings. Das Sortieren dieser Boxen anhand des inneren Produkts zwischen dem Query-Vektor und dem Klassen-Embedding liefert uns ähnliche Objekte in den Datensätzen.
Es gibt jedoch eine Fallstrick, in den Sie geraten könnten, wenn Sie es schaffen, eine Speicherlösung zu entwerfen. Die tatsächliche Netzwerkausgabe ist etwas komplizierter als in der dargestellten Abbildung. Neben den beiden in der Abbildung gezeichneten Ausgaben erzeugt es auch einen Skalierungsfaktor und einen Verschiebungsskalar, um die Zuversicht in die Vorhersage zu vergrößern oder zu verkleinern. Die tatsächliche Vorhersageformel sollte also wie folgt geschrieben und vereinfacht werden:
Kehren wir zum Code zurück. Wie üblich bereiten wir das Bild für die Eingabe des Modells vor.
from transformers import OwlViTProcessor, OwlViTForObjectDetection
name = "google/owlvit-base-patch32"
model = OwlViTForObjectDetection.from_pretrained(name)
processor = OwlViTProcessor.from_pretrained(name)
# Bild vorverarbeiten
ret = processor(text=txt, images=img, return_tensor='pt')
img = ret['pixel_values'][0]
Wir haben OWLViT ein wenig angepasst, weil wir das Bildmerkmal und die Boxen manuell mit der vorherigen Formel extrahieren möchten.
def extract_visual_feature(img):
with torch.no_grad():
model.eval()
# Merkmal aus ViT extrahieren
vision_outputs = model.owlvit.vision_model(
pixel_values=img,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
use_hidden_state=False,
)
last_hidden_state = vision_outputs[0]
image_embeds = model.owlvit.vision_model.post_layernorm(
last_hidden_state)
# Klassentoken neu skalieren
new_size = tuple(np.array(image_embeds.shape) - np.array((0, 1, 0)))
class_token_out = torch.broadcast_to(image_embeds[:, :1, :], new_size)
# Bildembedding mit Klassentoken zusammenführen
image_embeds = image_embeds[:, 1:, :] * class_token_out
image_embeds = model.layer_norm(image_embeds)
# Auf [batch_size, num_patches, num_patches, hidden_size] skalieren
new_size = (
image_embeds.shape[0],
int(np.sqrt(image_embeds.shape[1])),
int(np.sqrt(image_embeds.shape[1])),
image_embeds.shape[-1],
)
image_embeds = image_embeds.reshape(new_size)
# Letzte versteckte Zustände aus Text- und Visionstransformatoren
vision_model_last_hidden_state = vision_outputs[0]
feature_map = image_embeds
batch_size, num_patches, num_patches, hidden_dim = feature_map.shape
image_feats = torch.reshape(
feature_map, (batch_size, num_patches * num_patches, hidden_dim))
# Objektboxen vorhersagen
pred_boxes = model.box_predictor(image_feats, feature_map)
image_class_embeds = model.class_head.dense0(image_feats)
image_class_embeds /= torch.linalg.norm(
image_class_embeds, dim=-1, keepdim=True) + 1e-6
# Eine erlernbare Verschiebung und Skalierung auf Logits anwenden
logit_shift = model.class_head.logit_shift(image_feats)
logit_scale = model.class_head.logit_scale(image_feats)
logit_scale = model.class_head.elu(logit_scale) + 1
prelogit = torch.cat([image_class_embeds * logit_scale,
logit_shift * logit_scale], dim=-1)
return prelogit, image_class_embeds, pred_boxes
# EXTRAHIEREN!
prelogit, image_class_embeds, pred_boxes = extract_visual_feature(
img.unsqueeze(0))
Und der Rest liegt bei Ihnen! Alles, was Sie tun müssen, ist, diese Daten zu speichern und sie in MyScale hochzuladen. Sie können unserer SQL-Referenz folgen, um Ihre eigenen Daten einzufügen!
# Beste Praxis für Speicher- und Abfrageentwurf
Wir haben zwei Arten von Instanzen: Boxen und Bilder. Boxen gehören zu Bildern. Es ist also effizienter und flexibler, die Daten in zwei Tabellen zu speichern.
# Speicherentwurf
# Bildtabelle
| SPALTE | DTYPE | |
|---|---|---|
| img_id | String | PRIMARY |
| img_url | String | |
| img_w | Int32 | |
| img_h | Int32 |
# Objekt-Tabelle
| SPALTE | DTYPE | |
|---|---|---|
| obj_id | String | PRIMARY |
| img_id | String | (FOREIGN) |
| box_cx | Float32 | |
| box_cy | Float32 | |
| box_w | Float32 | |
| box_h | Float32 | |
| class_embedding | Array(Float32) | Länge = 512 |
| prelogit | Array(Float32) | Länge = 513 |
SQL zur Tabellenerstellung:
CREATE TABLE IMG_TABLE (
`img_id` String,
`img_url` String,
`img_w` Int32,
`img_h` Int32
) ENGINE = MergeTree PRIMARY KEY img_id
ORDER BY
img_id SETTINGS index_granularity = 8192
CREATE TABLE OBJ_TABLE (
`obj_id` String,
`img_id` String,
`box_cx` Float32,
`box_cy` Float32,
`box_w` Float32,
`box_h` Float32,
`logit_resid` Float32,
`class_embedding` Array(Float32),
`prelogit` Array(Float32),
CONSTRAINT cls_emb_len CHECK length(class_embedding) = 512,
CONSTRAINT prelogit_len CHECK length(prelogit) = 513,
VECTOR INDEX vindex prelogit TYPE MSTG('metric_type=IP')
) ENGINE = MergeTree PRIMARY KEY obj_id
ORDER BY
obj_id SETTINGS index_granularity = 8192
Wir haben MSTG als unseren Vektor-Suchalgorithmus verwendet. Für Konfigurationsdetails siehe Vector Search.
# Abfrage-Design
Wir behandeln jeden Ausdruck des Benutzers als eine einzelne Abfrage und holen die Top-K für jede davon. Diese Abfragen sollten nach Bildern gruppiert und auch nach einer kombinierten Punktzahl sortiert werden. Zum Beispiel sollte ein Bild, das mehrere relevante Objekte enthält, höher eingestuft werden als ein Bild, das nur ein relevantes Objekt enthält. Daher müssen wir auch SQL verwenden, um das zu berechnen.
# Unterabfragen: Vermeidung von zu vielen Lesevorgängen in der großen Daten-Spalte
Für jede Textabfrage, die wir erhalten, fragen wir class_embedding, vorhergesagte Boxen und Konfidenz sowie Informationen zu den Bildern ab. Die Spalte class_embedding ist in normalen Anwendungen eigentlich nicht notwendig. Aber für einen Few-Shot-Learner wie diesen benötigen wir diese Originalvektoren, um unsere Klassifikatoren zu trainieren. Das stellt uns vor eine Herausforderung bei der Behandlung großer Daten-Spalten und der Suche nach ihnen mit mehreren Vektoren und auch der Reduzierung des unnötigen Netzwerkverkehrs zur Steigerung der Geschwindigkeit. Es ist ein gutes Beispiel für fortgeschrittenes Abfrage-Design und -Optimierung.
Intuitiv können wir mit unserer Vektor-Abstandsfunktion unser SQL wie folgt zusammensetzen, um unser Ziel zu erreichen:
-- Zum Beispiel haben wir eine Abfrage mit dem Label `0` und _xq0 als unseren Abfragevektor
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l,
distance('nprobe=32')(prelogit, {_xq0}) AS dist
FROM OBJ_TABLE
JOIN IMG_TABLE
ON OBJ_TABLE.img_id = IMG_TABLE.img_id
ORDER BY dist DESC LIMIT 10
Das ist korrekt, aber nicht effizient. Diese Abfrage liest alle Spalten, einschließlich der riesigen Vektordaten, die in der Spalte class_embedding gespeichert sind. Das wäre eine Katastrophe und würde die Suchgeschwindigkeit in den Keller ziehen. Sie müssten auf die Daten warten, die von der Datenbank gelesen werden, um Ihr Ergebnis zu erhalten. Daher müssen wir die Art und Weise ändern, wie wir abfragen.
Das eigentliche Ziel unserer Abfrage ist es, die nächsten Nachbarn des Abfragevektors und ihre Informationen abzurufen. Wir können es in zwei Schritte aufteilen, mit anderen Worten, in zwei Unterabfragen. Zuerst erhalten wir die obj_ids dieser Boxen und dann die Boxpositionen und -einbettungen. WHERE ist auch praktisch, um unnötige Daten herauszufiltern. Die verbesserte Abfrage sieht so aus:
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
WHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
)
Wir verwenden WHERE, um nicht-TopK-Objekte vor dem Zusammenführen der Bildtabelle und der Objektetabelle herauszufiltern. Dadurch werden Tonnen von Lesevorgängen in der Spalte class_embedding vermieden. Nachdem wir diese ungenutzten Daten entfernt haben, können wir das, was wir für die Abfrage benötigen, leicht lesen. Großartig, wir haben eine schnelle und funktionale Abfrage zur Hand!
# Gruppierung von Unterabfragen
Erstens müssen wir alle Unterabfragen vor dem Gruppieren zusammenführen. UNION ALL (opens new window) ist hilfreich, wenn Sie mehrere Unterabfragen sammeln müssen. Außerdem wissen wir, dass einige Bilder mehrere Objekte enthalten können. Wir möchten nicht, dass die Boxen über die Ergebnisse verstreut sind, daher müssen wir sie gruppieren. Jetzt ist es an der Zeit, die GROUP BY-Klausel zu verwenden. Sie müssen jede abgefragte Spalte entweder unter einer Aggregatfunktion oder nach dem GROUP BY platzieren. In diesem Szenario verwenden wir groupArray (opens new window), das alle gruppierten Ergebnisse in ein Array zusammenfügt. Die endgültige Version unserer Abfrage sieht also wie folgt aus:
SELECT img_id, groupArray(obj_id) AS box_id, img_url, img_w, img_h,
groupArray(box_cx) AS cx, groupArray(box_cy) AS cy,
groupArray(box_w) AS w, groupArray(box_h) AS h,
groupArray(l) as label, groupArray(class_embedding) AS cls_emb
FROM (
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 0 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
PREWHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq0}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
)
UNION ALL
SELECT img_id, img_url, img_w, img_h,
obj_id, box_cx, box_cy, box_w, box_h, class_embedding, 1 AS l
FROM OBJ_TABLE
JOIN IMG_TABLE
ON IMG_TABLE.img_id = OBJ_TABLE.img_id
PREWHERE obj_id IN (
SELECT obj_id FROM (
SELECT obj_id, distance('nprobe=32')(prelogit, {_xq1}) AS dist
FROM OBJ_TABLE
ORDER BY dist DESC
LIMIT 10
)
))
GROUP BY img_id, img_url, img_w, img_h
# Reduzierung des Netzwerkverkehrs zwischen Ihrer Anwendung und MyScale
Anwendungen können mit einer schwachen Netzwerkverbindung gestrandet sein, und nehmen wir an, Sie können nichts dagegen tun. Wenn das passiert, verzweifeln Sie nicht. MyScale ist mächtiger, als Sie sich vorstellen können. Die Reduzierung des Netzwerkverkehrs wird Ihr einziges Ziel sein, aber wie? Wenn Sie keine Einbettungsdaten abrufen, können Sie den Gradienten nicht auf Ihrem Server berechnen... Tatsächlich muss diese Berechnung nicht unbedingt auf Ihrem Server durchgeführt werden, sie kann auch in der Datenbank erfolgen. Da sie die Ausgabe des Netzwerks mit der Ausgabe der Zwischenschicht berechnen und sortieren kann, können Sie erwarten, dass sie auch den Gradienten berechnet. Die Berechnung des Gradienten kann Ihnen helfen, das Abrufen von Einbettungen direkt aus der Datenbank zu vermeiden, was normalerweise mehr als 20 MB Daten für eine einzelne Abfrage erfordert. Das könnte bei einer Bandbreite von 10 Mbps bis zu 20 Sekunden dauern. Das ist in einigen Szenarien völlig inakzeptabel.
Schauen wir uns an, wie das gemacht werden kann. Nehmen wir an, wir haben die binäre Kreuzentropie als Verlustfunktion zur Schulung des Few-Shot-Klassifikators übernommen. Wir können trivialerweise
berechnen, wobei
SELECT sumForEachArray(arrayMap((x,p,y)->arrayMap(i->i*(p-y), x), X, P, Y)) AS grad FROM (
SELECT groupArray(arrayPopBack(prelogit)) AS X,
groupArray(1/(1+exp(-arraySum(arrayMap((x,y)->x*y, prelogit, <your-weight>))))) AS P,
<your-label> AS Y
FROM <your-db>
WHERE obj_id IN [<your-objects>]
)
Das obige SQL kann Ihnen den Gradienten sofort geben. Ihre Anwendung muss sich nur um den Rest kümmern: die Anwendung dieses Gradienten mit einer Lernrate. Glauben Sie mir, dieser Trick ist SUPER schnell.
# Fortgeschrittene Verwendung von Array-Funktionen
Während der Abfrage müssen wir Daten berechnen, die in keiner Spalte vorhanden sind. Im Gegensatz zu Aggregationen (opens new window) müssen wir elementweise auf Array-Objekten rechnen. Hier kommen also die Array-Funktionen (opens new window) ins Spiel. Clickhouse bietet viele praktische Funktionen, die uns bei der Manipulation von Arrays helfen. Die Vektor-Suchalgorithmen von MyScale sind mit Clickhouses Array (opens new window) kompatibel. Sie können also alle Array-Funktionen in Clickhouse nutzen. Hier haben wir zwei Beispiele, um zu zeigen, wie Array-Funktionen verwendet werden können.
# Berechnung der Vorhersagegenauigkeit
Wenn wir uns an die obige Formel erinnern, wird die Genauigkeit der Vorhersage als ein inneres Produkt berechnet, das von einer Sigmoid-Funktion abgebildet wird. Hier verwenden wir arrayMap (opens new window) und arraySum (opens new window), um das endgültige Logit zu berechnen. Die Berechnungsfunktion sieht so aus:
SELECT 1/(1+exp(-arraySum(arrayMap((x,y)->x*y, prelogit, {_xq0})))) AS pred_logit
FROM OBJ_TABLE LIMIT 10
Die Map-Funktion multipliziert elementweise zwei Arrays: _xq0 und jedes Array aus der Spalte prelogit. Diese Funktion kann entweder einzelne Arrays oder Arrays aus einer Spalte verarbeiten.
# Berechnung der Bildpunktzahl
Um dem Benutzer eine bessere Erfahrung zu bieten, sollten wir die Bilder nach ihrer Gesamtrelevanz sortieren. Hier geben wir ein einfaches Beispiel, um die Gesamtrelevanz des Bildes mit ClickHouse-Array-Funktionen zu beschreiben. In diesem Abschnitt stellen wir arrayReduce (opens new window) vor. Diese Funktion ist eine Gruppe von Funktionen, von denen eine maxIf ist. Sie kann den maximalen Wert in einem Array unter Berücksichtigung einer gegebenen Maske berechnen.
Wir definieren unsere Gesamtbildrelevanz als eine Summe des maximalen Klassenlogits. Um konkreter zu sein, berechnen wir zuerst den maximalen Vertrauenswert für ein Klassenlabel und summieren sie dann auf. Das bedeutet, je mehr Klassen Sie im Bild haben, desto höher ist die Relevanz des Bildes. Außerdem ist die höhere maximale Vertrauenswürdigkeit desto höher die Relevanz.
Wir greifen auf das zuvor berechnete pred_logit zu und der Ausdruck sieht so aus:
arraySum(arrayFilter(x->NOT isNaN(x),
array(arrayReduce('maxIf', groupArray(pred_logit), arrayMap(x->x=0, label)),
arrayReduce('maxIf', groupArray(pred_logit), arrayMap(x->x=1, label)))))
Zuerst berechnen wir eine Maske für ein gegebenes Label mit der Funktion arrayMap und verwenden sie dann, um den maximalen Wert für jedes Label in der Abfrage des Benutzers zu berechnen.
Wir wandeln die Menge der berechneten Maximalwerte in ein Array um und berechnen ihre Summe, wenn einer ihrer Werte nicht Nan ist. Dadurch erhalten Sie sofort die Gesamtpunktzahl des Bildes.
# Zum Schluss
Dieses Tutorial gibt Ihnen ein Beispiel für die fortgeschrittene Verwendung von MyScale. Es umfasst Unterabfragen, Gruppierung, Array-Funktionen und effizientes SQL-Design in MyScale. Hier sind einige Erkenntnisse, die nützlich sein könnten:
- Für komplexe Vektorabstände: Versuchen Sie, es MyScale leicht zu machen. Die meisten Abstandsfunktionen können immer in einen L2-Abstand, einen Kosinusabstand oder ein Skalarprodukt umgewandelt werden. Stellen Sie sicher, dass Sie wissen, mit welcher Funktion Sie arbeiten werden.
- Für komplexe Vektor-SQL: Lassen Sie die großen Vektorspalten hinter sich und verarbeiten / lesen Sie zuerst die kleinen Spalten.
- Für fortgeschrittene Berechnungen: Array-Funktionen sind immer Ihre besten Freunde. Das Berechnen dieser Zahlen mit SQL gibt Ihnen zusätzliche Leistung: Sortieren/Auswählen wird billig, wenn Sie es innerhalb von MyScale tun, und spart Ihnen auch ein paar Cent pro Tag durch weniger Berechnungen auf einem Webserver.